はじめに
単一回の生成における問題点
画像生成における目覚ましい進歩にもかかわらず、現在のモデルは依然として基本的な視覚的論理において脆弱であり、妥当性はあるものの誤った画像を生成する可能性があります。例えば、「スプーンの上に浮いているクマ」というプロンプトに対して、モデルが正しくない結果として「クマがスプーンのそばに立っている」という画像を生成してしまうことがあります。このようなワンショットのブラックボックス生成は、モデルに単一のフォワードパスの中で、正確な空間配置、オブジェクト間の関係、そして細部の属性をすべて同時に解決することを強いることになります。
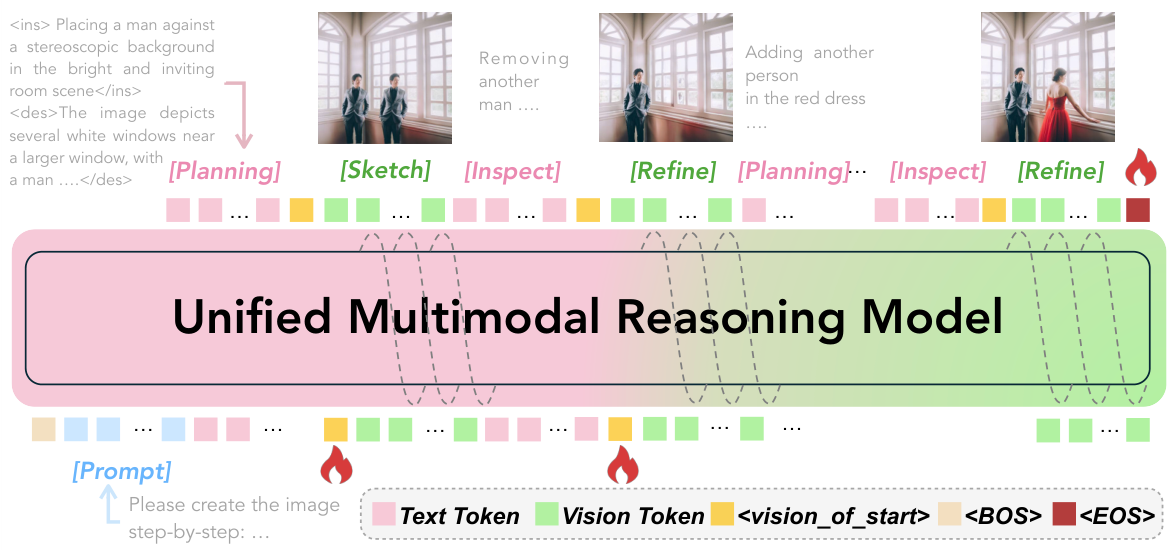
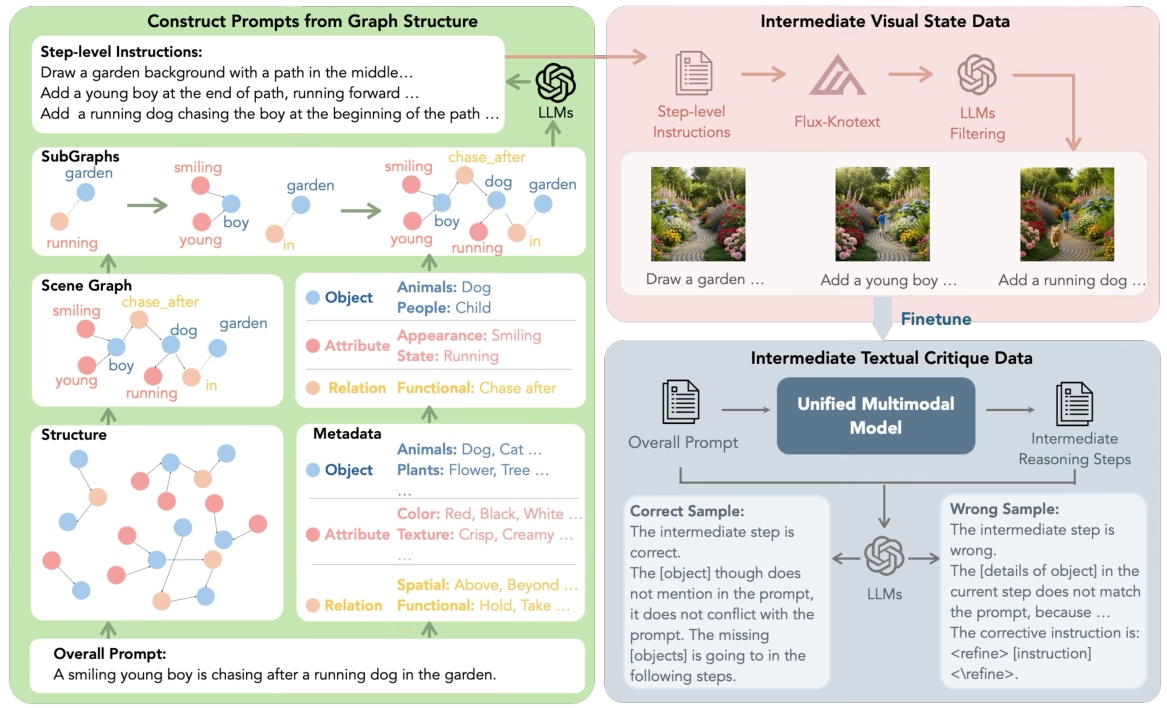
私たちのアプローチ:プロセス駆動型生成
私たちは、ビジョンとテキストの両方に根ざした、交互推論によるプロセス駆動型画像生成によって、この成果志向のパラダイムに挑戦します。我々は、画像生成を、テキストプランと視覚状態が共進化する軌道として再定義し、それを、繰り返される4段階のプロセスによって調整します。Plan → Sketch → Inspect → Refine。このモデルは、最終的な画像を思い描くのではなく、画像を描画する際に、一筆一筆、決定ごとに構築していきます。