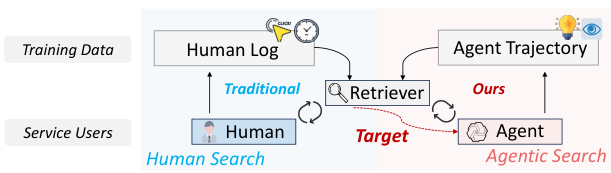
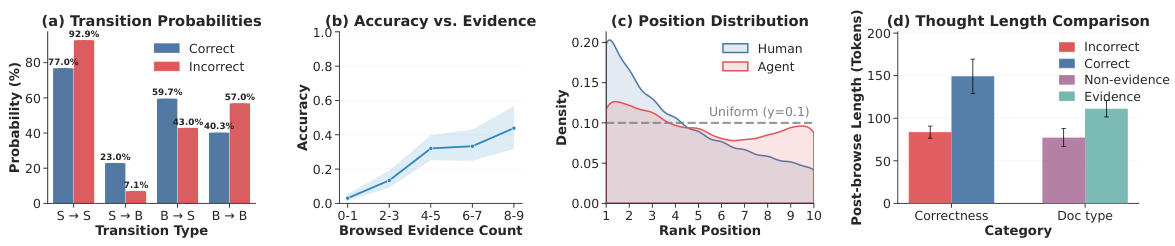
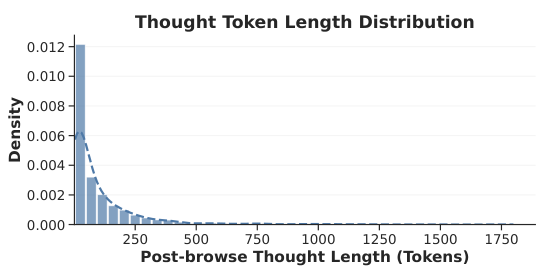
各々の軌跡は、エージェントの意思決定プロセス全体を捉えています。具体的には、エージェントが閲覧を選択したドキュメント、拒否したドキュメント、そして各ドキュメントに対してどれだけの推論を費やしたかなどが記録されています。これらの詳細な行動データは、LRAT(Learning from Rational Agent Trajectories)の学習パラダイムの基礎をなしています。
LRATフレームワーク
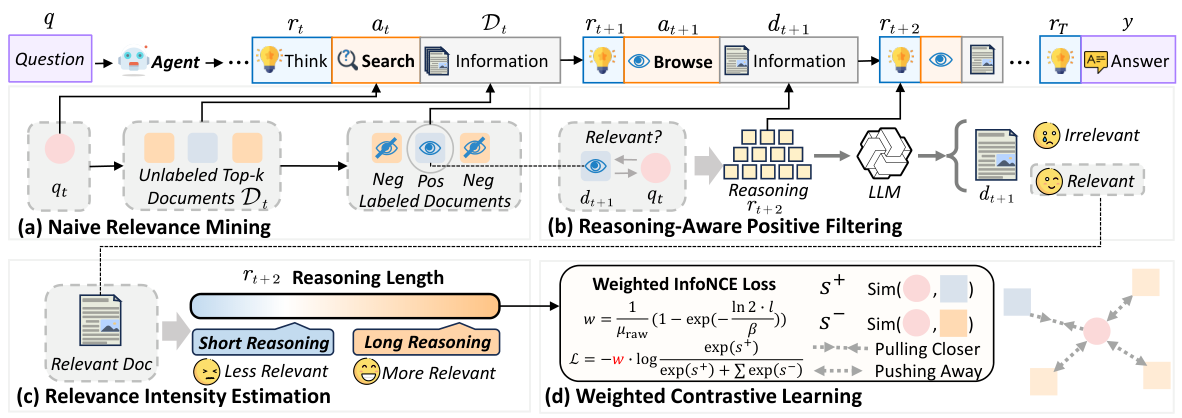
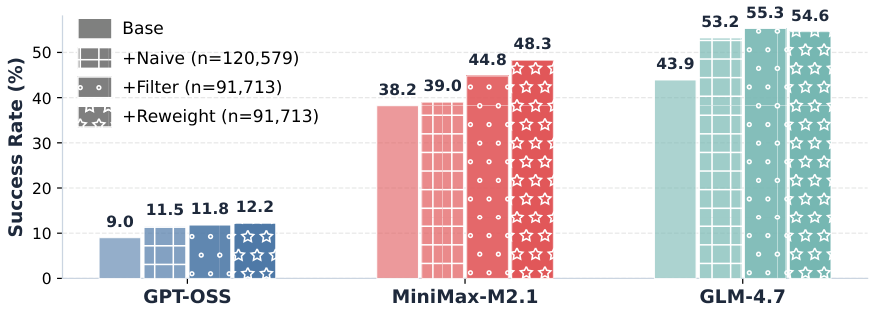
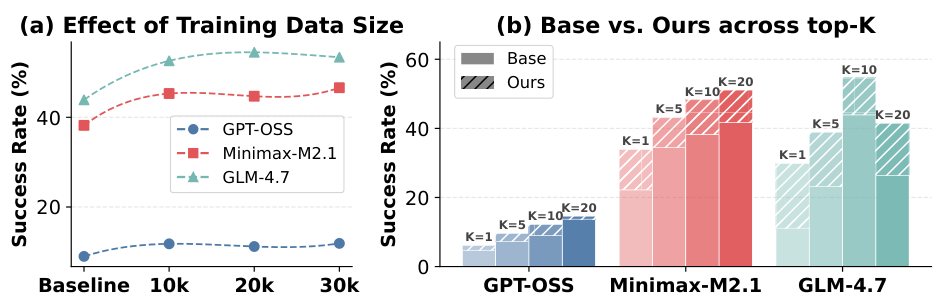
LRAT (Learning to Retrieve from Agent Trajectories) は、エージェントとのインタラクションから高品質な検索の教師信号を段階的に抽出し、ユーティリティを考慮した重み付けで検索モデルを訓練するフレームワークです。このフレームワークは、以下の4つの主要な構成要素を持っています。
InfoNCE Loss は、コントラスティブ学習における標準的な学習目標です。これは、多肢選択式のテストのように機能します。モデルは、与えられたクエリに対して、候補となる文書の集合の中から正しい文書を選択する必要があります。LRATにおける「重み付き」バージョンでは、正解の中には、他の正解よりも重要度が高いものがあります。エージェントがより深い推論を誘発した文書には、より高い重みが与えられ、モデルが真に価値のある結果を優先するように促します。
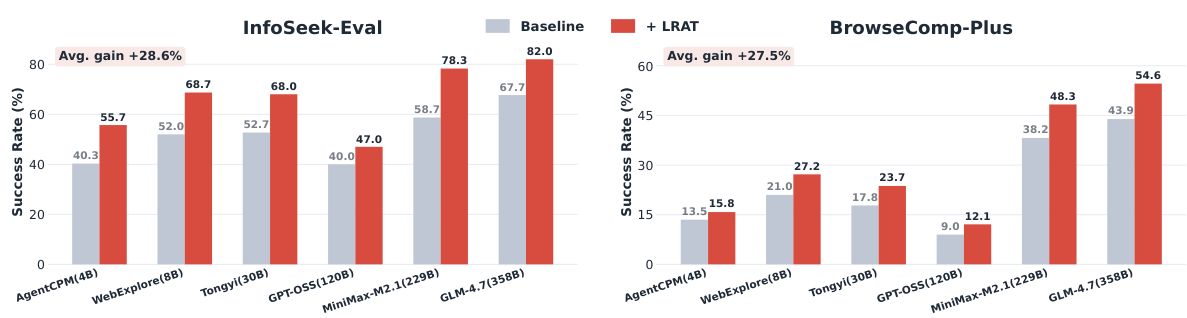
本論文では、人間中心の検索学習と、エージェントによる検索のニーズとの間に存在する根本的な不一致を指摘し、エージェントの軌跡からの検索学習を新たな検索パラダイムとして形式化しています。 LRAT(Learning from Agent Trajectories)は、エージェントのインタラクションデータには、検索品質、タスクの成功率、および多様なエージェントアーキテクチャにおける実行効率を大幅に向上させる可能性のある、豊かで信頼性の高い教師信号が含まれていることを示しています。