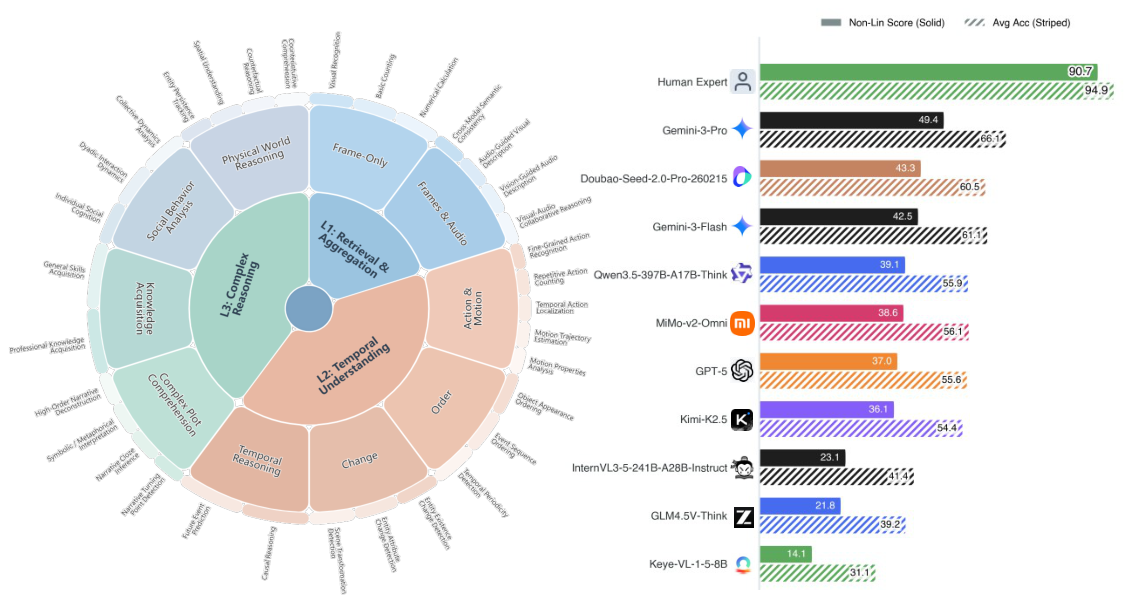
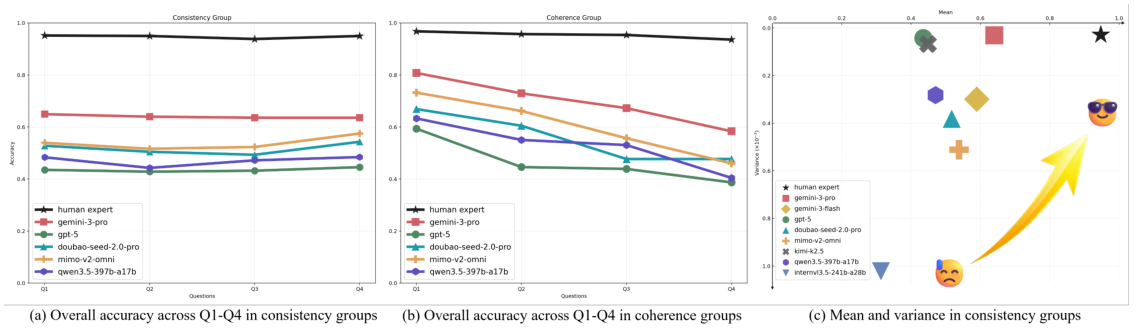
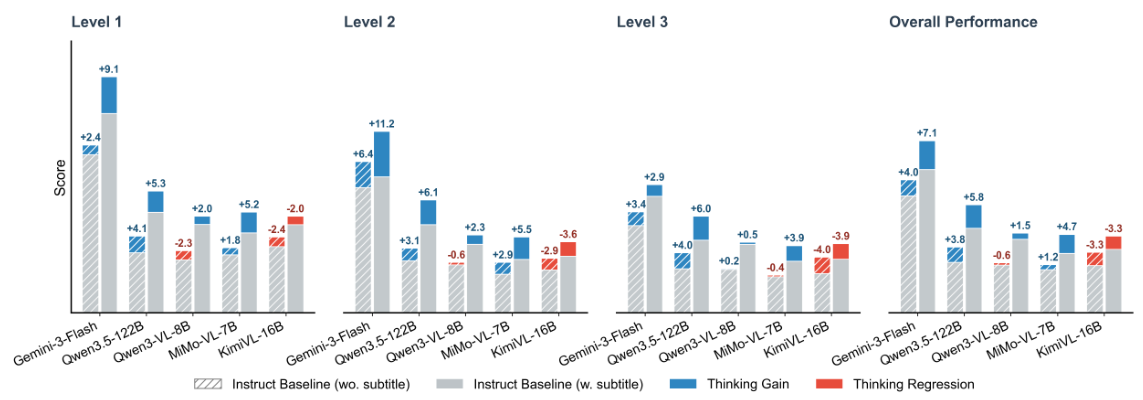
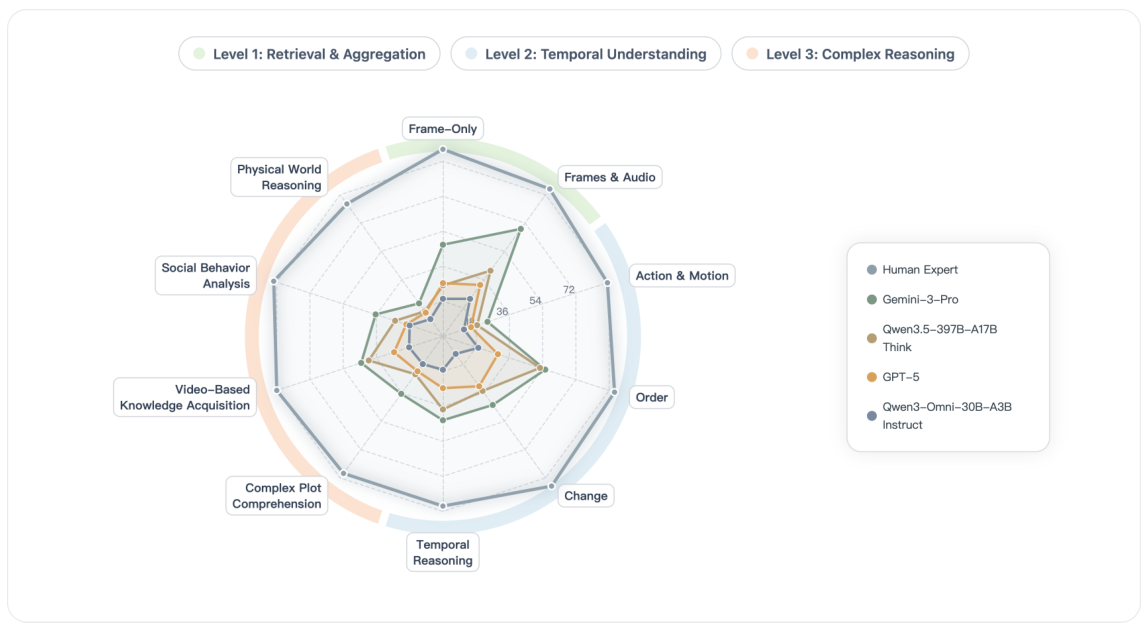
Dataset
データセット:多様で新鮮、厳格にアノテーション済み
5
主要カテゴリ
800
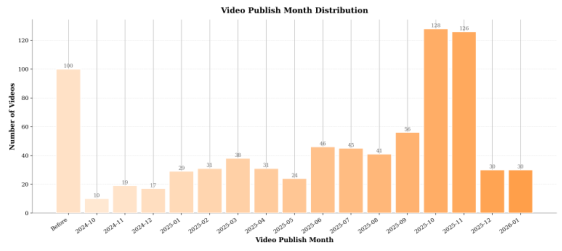
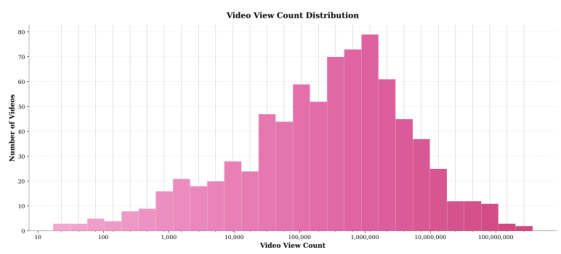
動画数
3,300+
人時アノテーション
5
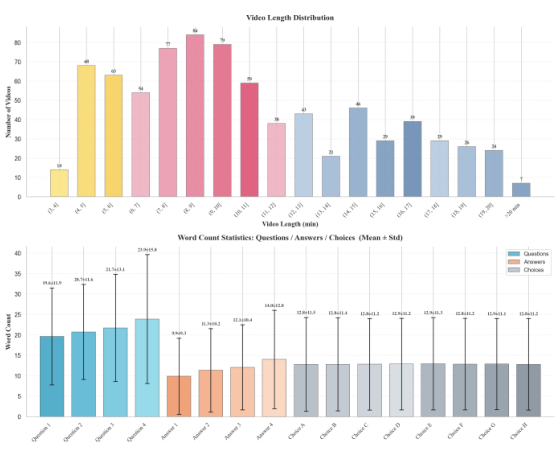
QAラウンド数
厳格なアノテーションパイプライン
データ品質は管理されたアノテーションパイプラインによって保証されている。12名のアノテーターが質問と正解を作成し、50名の独立レビュアーが最大5回の品質保証サイクルにわたりコンテンツを検証した。このプロセスにより、Video-MME-v2には表面的なパターンマッチングではなく真の動画理解を評価する、明確で高品質なベンチマーク項目のみが含まれる。
なぜ3,300時間が必要か?1本の動画のアノテーションに平均30分(視聴・質問作成・回答検証)かかるとすると、800本以上の動画のアノテーションには膨大な労力が必要だ。5回のQAプロセスにより、各項目は採用前に約50回レビューされたことになる。これは自動化やクラウドソーシングによるアノテーションを使う多くのベンチマークとは大きく異なる。