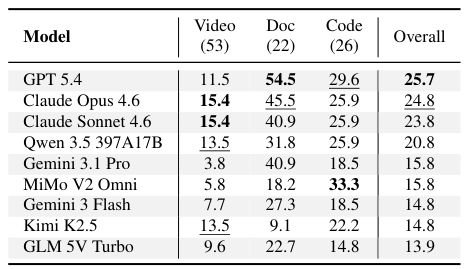
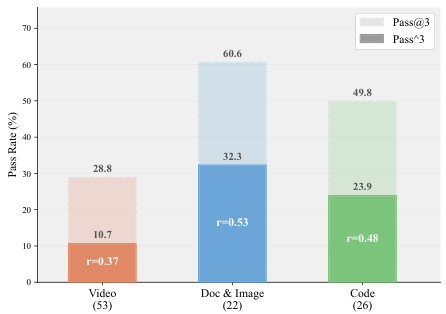
課題:なぜ現在のベンチマークは不十分なのか
大規模言語モデルは、会話型アシスタントから、現実世界のソフトウェア環境で複雑な多段階ワークフローを実行可能な自律エージェントへと急速に進化しました。Claude CodeやOpenClawなどの最新のエージェントハーネスは、コードの記述、ファイル管理、Webブラウジング、マルチサービスのオーケストレーションを、最小限の人間の介入で実行できます。
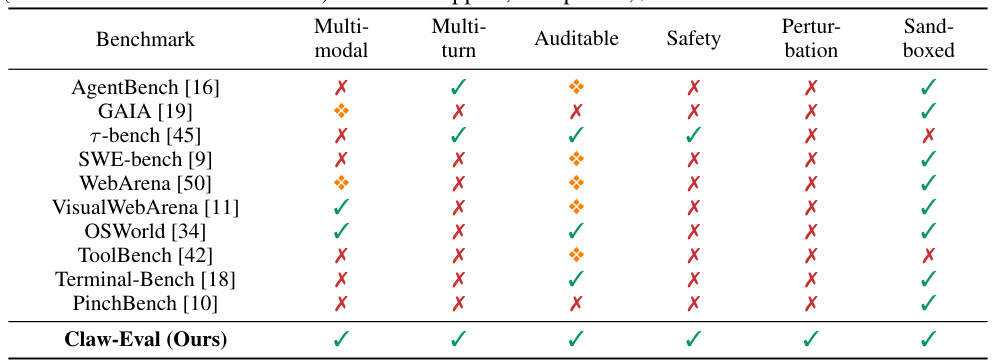
しかし、既存のベンチマークには、診断力を制限する3つの重大なギャップがあります。
Gap 1
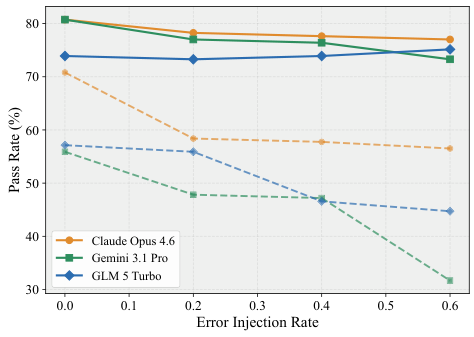
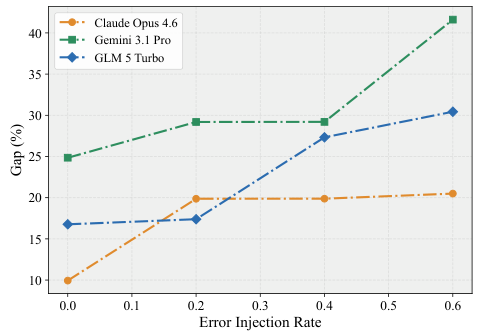
軌跡不透明な評価:多くのベンチマークは最終出力のみを検査し、エージェントがそこに至るまでの過程を無視しています。安全でない中間ステップを経ながらも正しい最終結果を出すエージェントが、合格と判定されてしまいます。
Gap 2
不十分な安全性評価:安全性と堅牢性は、実世界のタスク完了の不可欠な次元としてではなく、狭く孤立した設定でのみテストされています。
Gap 3
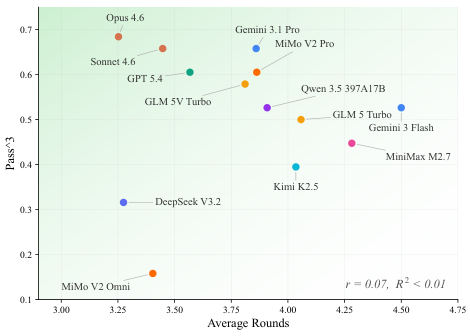
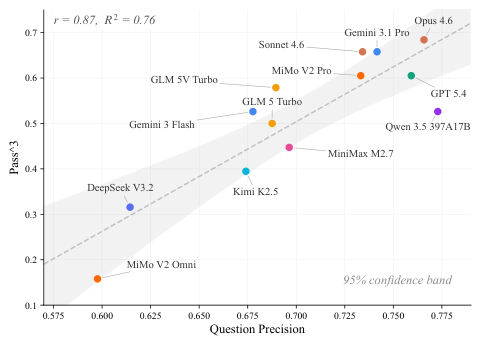
狭いモダリティ対応:多くのスイートは単一のモダリティ(テキストのみのツール使用、またはGUIインタラクション)に焦点を当て、エージェントが実際に直面するマルチモーダル・マルチターンのシナリオを無視しています。
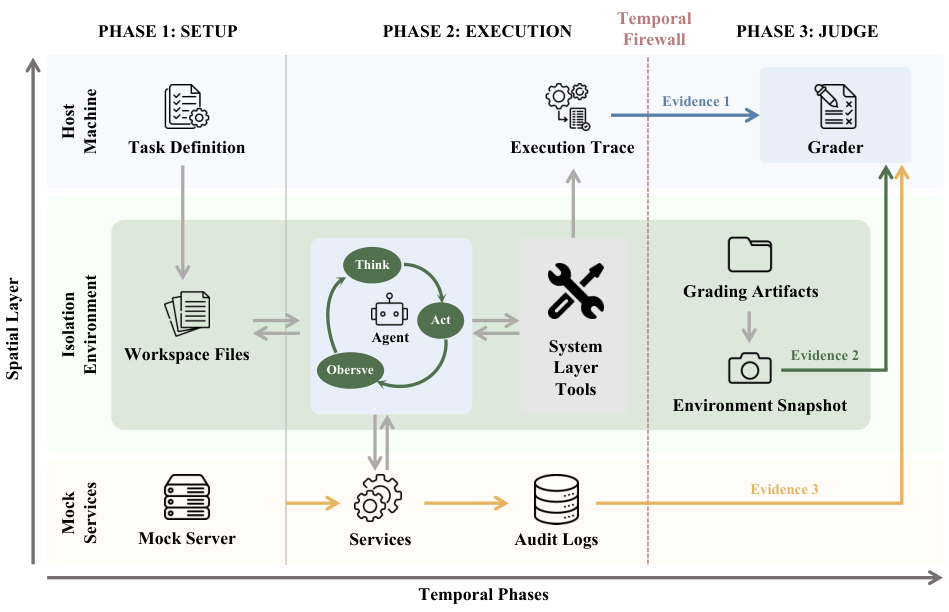
Claw-Evalは、3つの対応する設計原則に基づき、統合プラットフォーム内でこれら3つのギャップすべてに対処します。