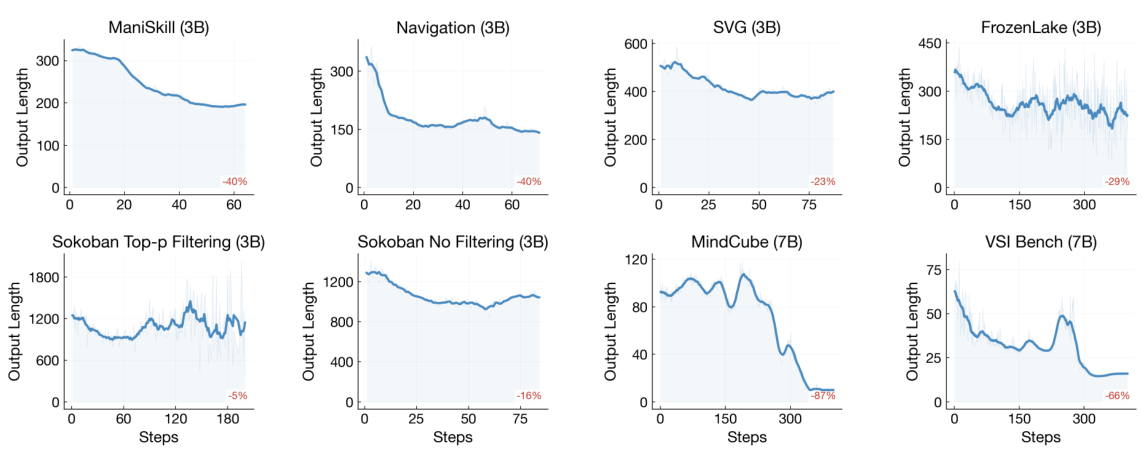
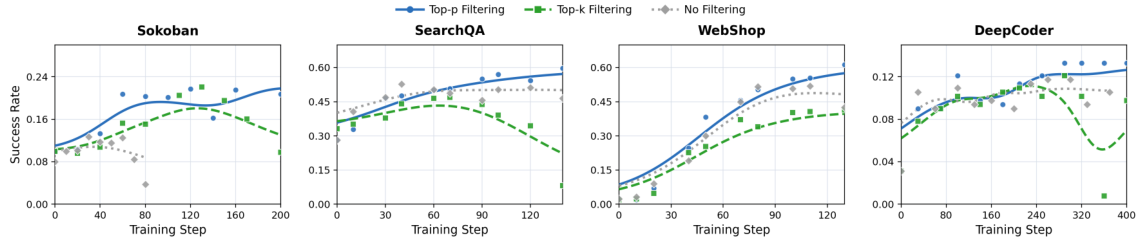
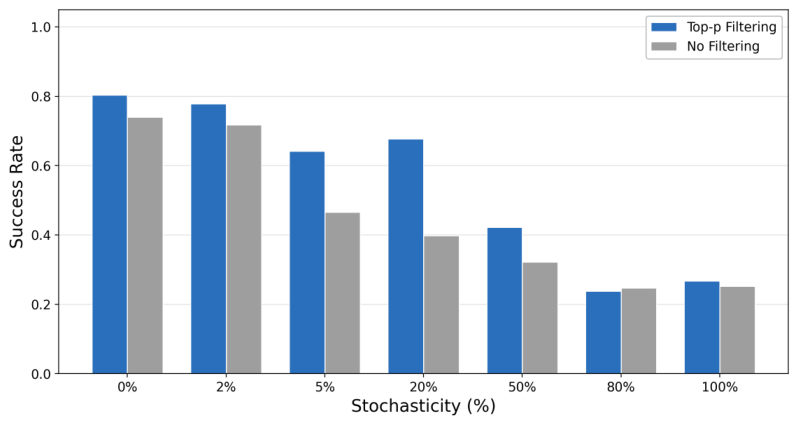
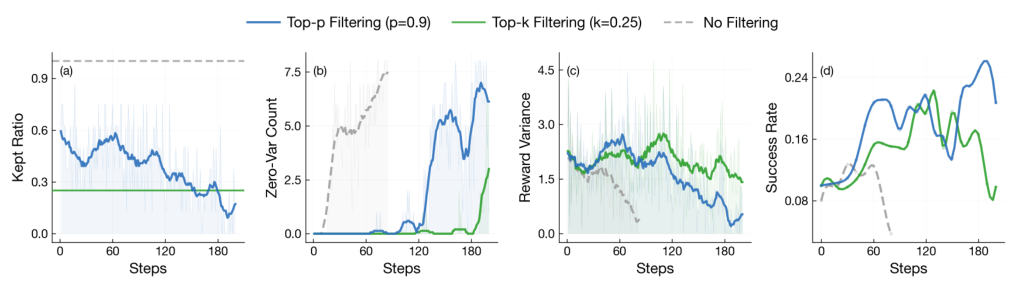
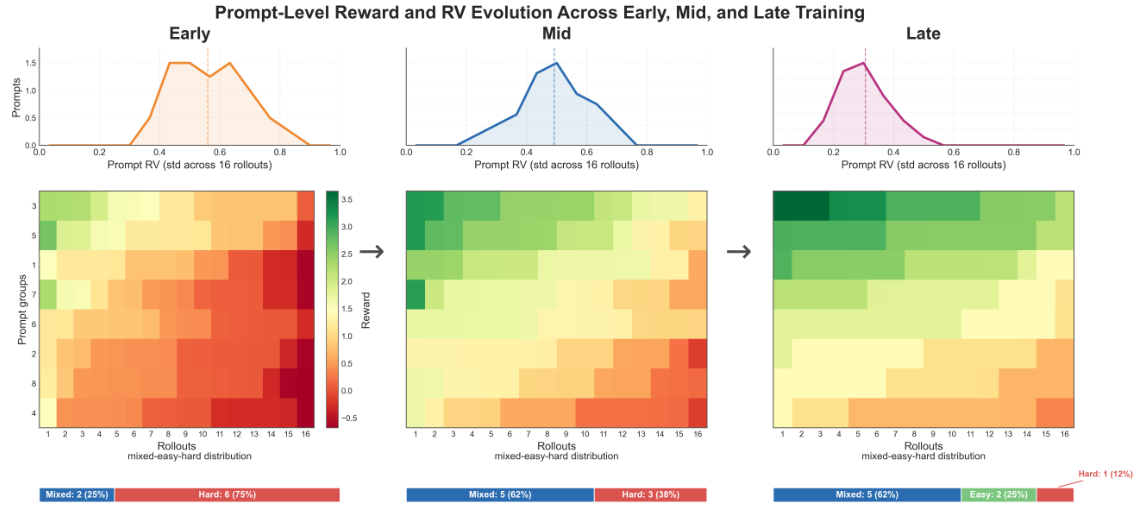
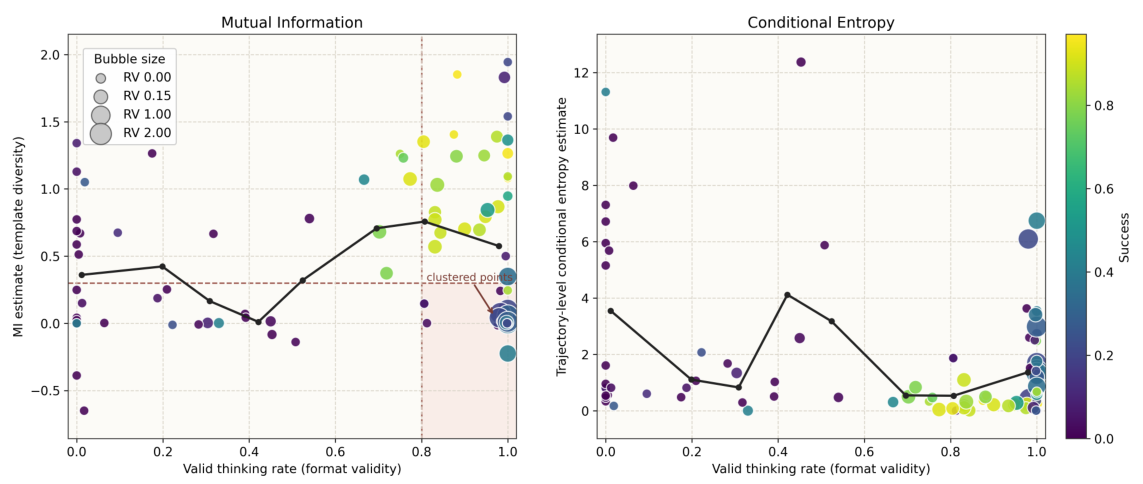
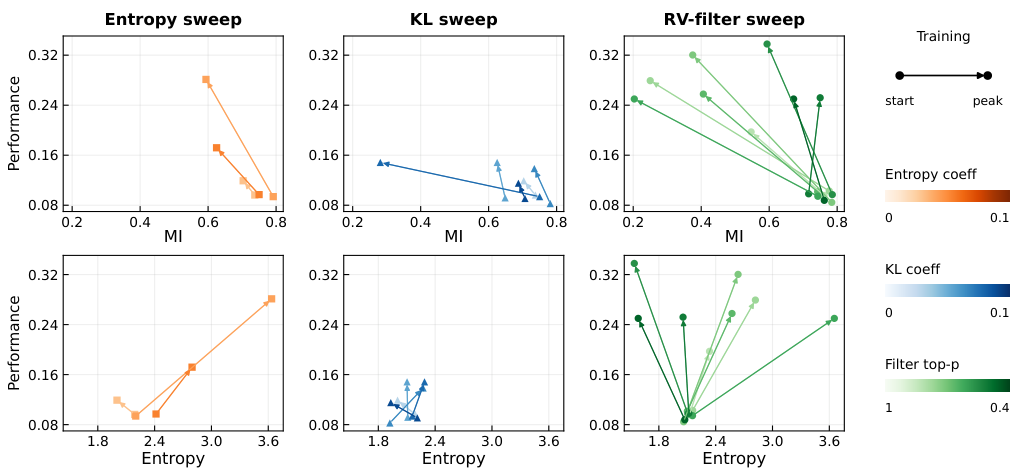
テンプレートの崩壊 — 失敗モード
2.1 テンプレートコラプスとは何ですか?
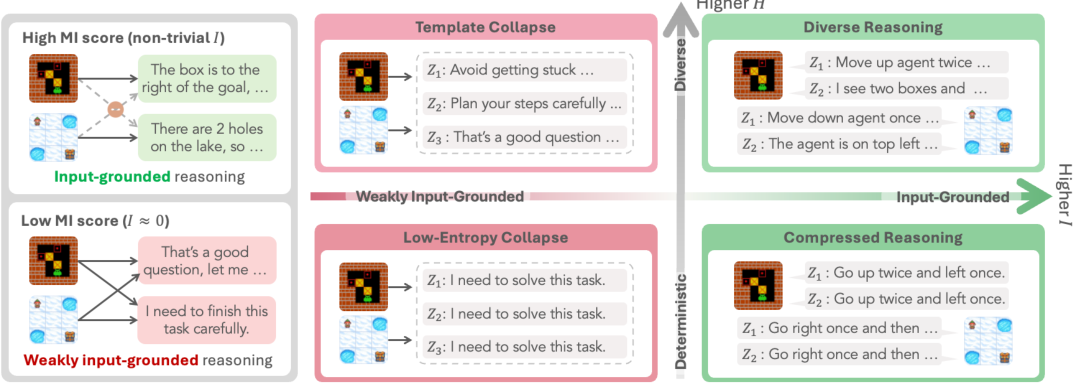
テンプレートの崩壊とは、強化学習によって訓練されたLLMエージェントが、入力に関わらず一貫して適用される固定された応答テンプレートの集合に収束する現象を指します。モデルは、例えば、"I need to solve the task step by step" や "Let me think about this carefully" のようなフレーズを、いかなる推論にも先立つ定型的な前置きとして出力することを学習し、結果的に入力特有の情報が無視されることになります。
この問題が巧妙なのは、標準的なエントロピー評価指標では検出できない点です。なぜなら、テンプレート自体が表面上は異なる場合があるからです(モデルはテンプレート表現のプールから選択します)。その結果、全体的なトークンの分布は多様に見えることがあります。しかし、出力が入力に依存しているかどうかを問い合わせたときに、初めてその問題が明らかになります。
2.2 相互情報量とエントロピー
重要な洞察は、2つの関連性はあるものの、異なる量との区別です。エントロピー H(Y) は、単一の入力における出力の多様性を測定します(プロンプト x に対する N 個のサンプルはどの程度変動するでしょうか?)、一方、相互情報量 MI(X;Y) は、入力にわたって出力が変化するかどうかを測定します(異なるプロンプトは、意味のある異なる応答を生み出すでしょうか?)。
入力Xと出力Yの間の相互情報量は、入力に関する情報が、出力に関する不確実性をどれだけ減少させるかを定量化するものです。
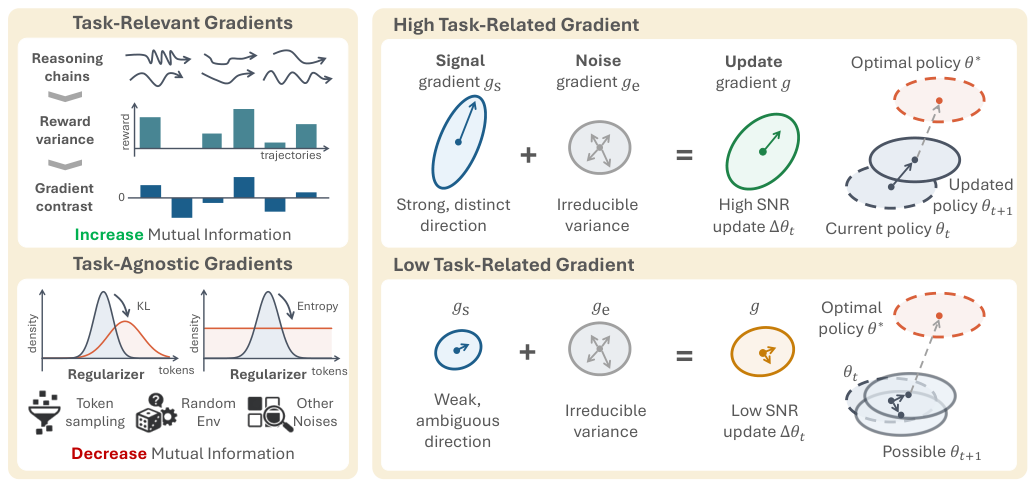
MI(相互情報量)は、等価的に、MI = H(Y) − H(Y|X) と表されます。MIが高い場合、異なる入力が実際に異なる出力をもたらします。一方、H(Y)が高いにもかかわらずMIが低い場合、モデルは入力に依存しない動作に陥り、これを「テンプレート崩壊(template collapse)」と呼びます。
この区別は非常に重要です。エントロピーは、入力内の多様性(同じプロンプトに対する複数の実行における変動)を測定します。一方、相互情報量(MI)は、入力間の識別可能性(エージェントが異なる状況に対して異なる反応を示すかどうか)を測定します。テンプレート崩壊は、高いH(Y)を示すものの、MIは低い傾向があります。これは、エージェントが固定されたテンプレート空間内で「創造的」であるものの、実際にはタスクに適切に反応していないことを意味します。
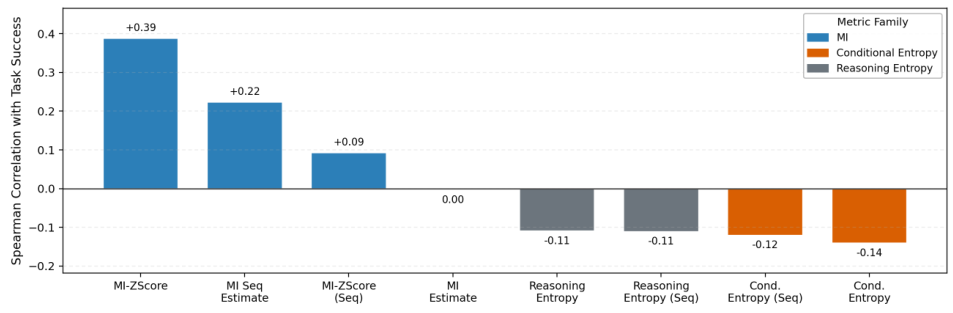
2.3 オンライン MI プロキシの指標
正確な相互情報量(MI)の計算はコストが高いため、RAGEN-2は、学習中に効率的に計算できるオンラインMIの近似値(プロキシ)のファミリーを提案しています。
MI-ZScore
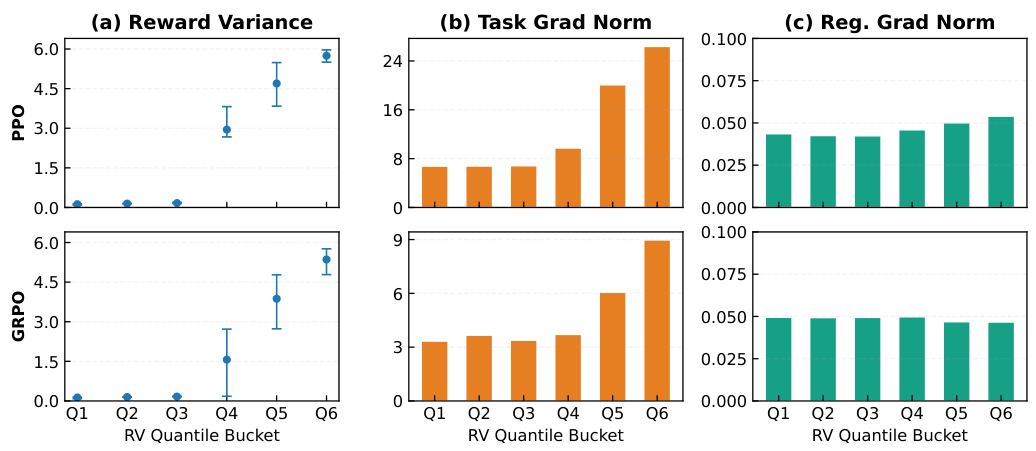
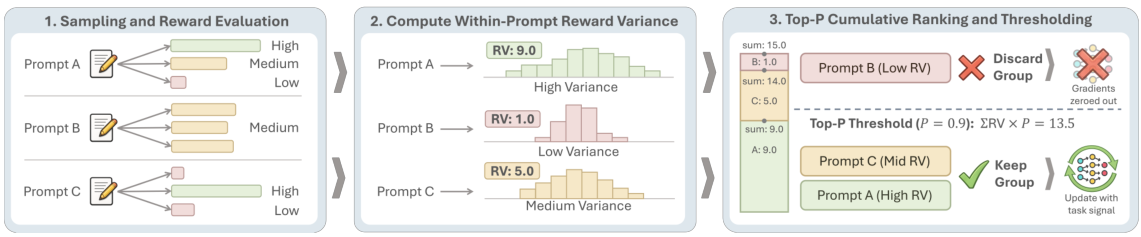
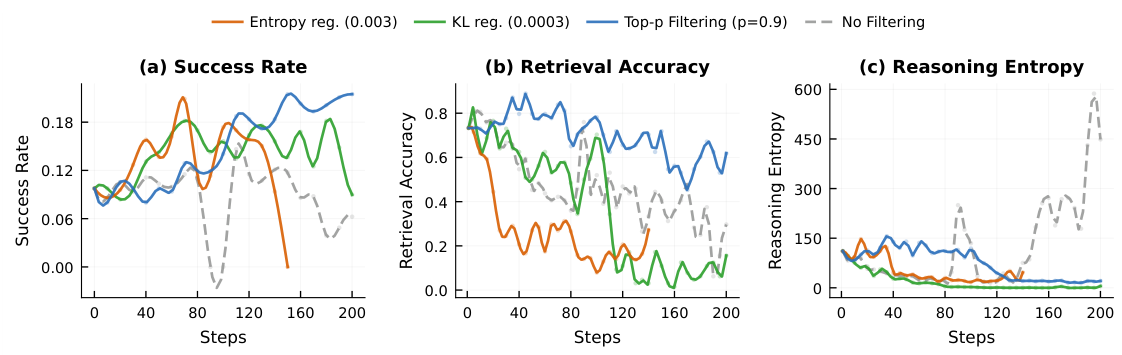
プロンプトごとの平均報酬を、Zスコアを用いて標準化します。報酬信号におけるプロンプト間のばらつきが大きい場合、入力依存的な挙動(高い相互情報量: MI)を示唆します。これが最もシンプルで効果的な指標です。
MI Seq Estimate
出力の連続的な構造から、異なるプロンプスにおける応答のユニークなプレフィックスの頻度を用いて、情報理論的な推定値としてMI(相互情報量)を直接推定します。
MI-ZScore (Seq)
Zスコアのアプローチと、シーケンスレベルでの推定を組み合わせることで、より堅牢なプロキシを実現し、可変長の応答やノイズの多い報酬信号にも対応します。