RefineAnything: 完璧なローカル詳細のためのマルチモーダル領域特定リファインメント
Abstract
アブストラクト
現代の画像生成モデルは、ローカル詳細の崩壊という根本的な問題を抱えています。固定解像度でエンコードする際、小さな領域はわずかな潜在トークンしか持てず、デコード時に細部を復元できません。その結果、AI生成画像に判読不能なテキスト・ぼやけた顔・不正確なロゴが生じます。
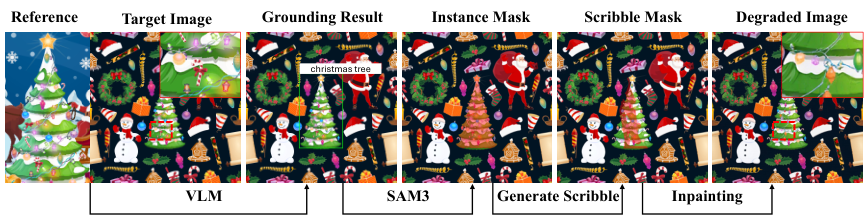
RefineAnythingは領域特定画像リファインメントを専用の問題設定として定式化します。入力画像とユーザー指定の領域(スクリブルマスクまたはバウンディングボックス)を受け取り、指定領域の細粒度な詳細を復元しつつ、それ以外のピクセルを完全に保持します。凍結されたQwen2.5-VLマルチモーダルエンコーダ、新しいFocus-and-Refineのクロップ・アップサンプル・デノイズ戦略、シームレスな統合のためのBoundary Consistency Lossを使用します。学習にはRefine-30K(30Kサンプル:参照ベース20K・参照なし10K)、評価にはこのタスク初のベンチマークRefineEvalを使います。
- 領域特定リファインメントを専用の問題設定として定義
- Focus-and-Refine:クロップ → アップサンプル → デノイズ → ペーストバック
- シームレスな統合のためのBoundary Consistency Loss
- Refine-30K:30Kトレーニングサンプル(参照ベース + 参照なし)
- RefineEval:領域特定リファインメント初のベンチマーク

Section 1
1. はじめに
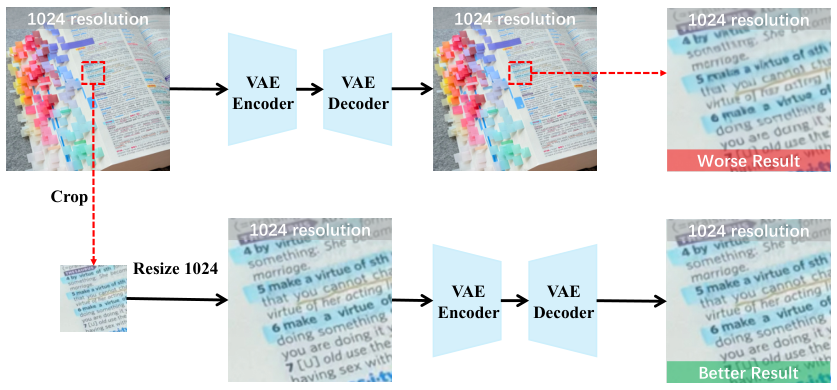
画像生成は劇的に進歩しましたが、根本的なボトルネックが残っています。それがVAE情報損失です。拡散モデルが画像をエンコードする際、小さな領域はわずかな潜在トークンしか占有できず、エンコーダはそれらを激しく圧縮します。その結果、読めるテキスト・識別可能なロゴ・くっきりとした顔の特徴という細部情報をデコード時に回復できません。
InstructPix2PixやSDEditなどの既存編集モデルは画像領域を変更できますが、周囲のコンテキストを保持しません——編集が周辺ピクセルに漏れ出してしまいます。FLUX Kontextはコンテキスト保持を改善していますが、外科的なローカル詳細回復には設計されていません。RefineAnythingは、この正確な問題に特化した初のシステムです。
新しい問題設定
領域特定画像リファインメントの形式的定義:画像+ユーザー指定領域が与えられたとき、他のすべてのピクセルを完全に保持しながら詳細を復元する。
RefineAnythingシステム
Focus-and-RefineでVAE解像度ボトルネックを解決し、Boundary Consistency Lossでシームレスなペーストバックを実現し、マルチモーダルVLMコンディショニングでリファインメントを誘導します。
Refine-30K + RefineEval
参照ベースと参照なしの両モードをカバーする30Kトレーニングサンプル、そして領域特定リファインメントを評価するための初の専用ベンチマーク。
Section 3
3. 手法
RefineAnythingはQwen2.5-VLでコンディショニングされた拡散バックボーン上に構築されています。入力として:(1) 劣化した領域を含む入力画像、(2) 領域がどう見えるべきかを示すオプションの参照画像、(3) 領域キュー(スクリブルマスクまたはバウンディングボックス)、(4) テキスト指示を受け取ります。出力は、指定された領域のみが精製された入力と同一の画像です。
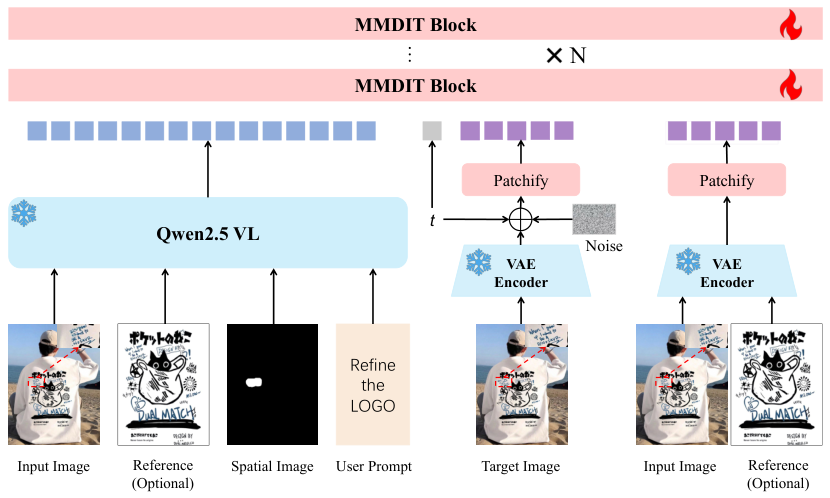
3ステップパイプライン
マルチモーダルエンコーディング
Qwen2.5-VL(凍結)が完全な入力画像・オプションの参照画像・領域キュー・テキスト指示をマルチモーダルコンディショニングトークンにエンコードします。これらのトークンが拡散バックボーンに「領域がどう見えるべきか」というセマンティックな誘導を与えます。
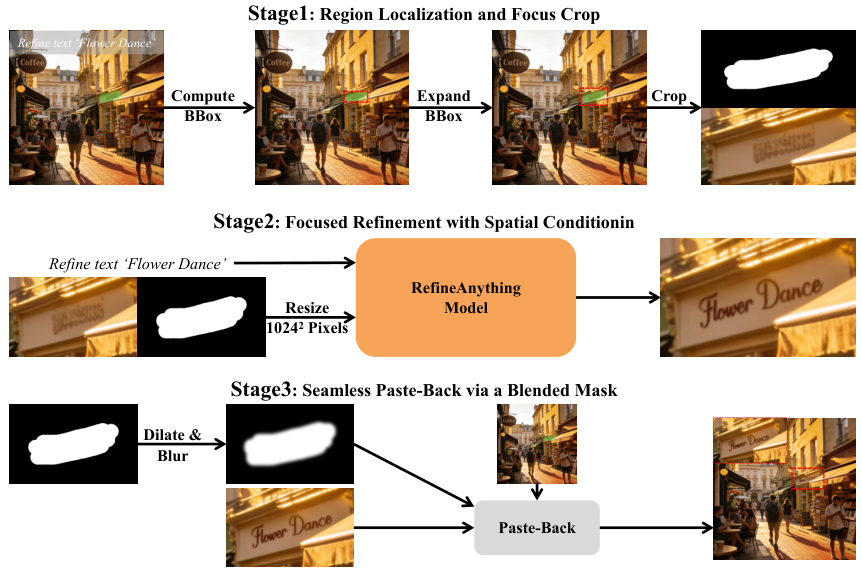
Focus-and-Refine
指定された領域をクロップし、フル解像度にアップサンプリングします。この高解像度空間で拡散デノイズを実行します。小さな対象領域をエンコーダにフル解像度で見せることで、VAE情報損失問題を解決し、細粒度の詳細回復を可能にします。
シームレスなペーストバック
精製された領域を元の画像にペーストバックします。トレーニング中に適用されるBoundary Consistency Lossが、領域境界での目に見える不連続を抑制します。結果として、精製された領域が自然に統合され、シームや光輪アーティファクトが生じません。
Refine-30K データセット
RefineAnythingをトレーニングするために、著者らはRefine-30Kを構築しました——領域特定画像リファインメント専用の初のトレーニングデータセットです。製品上のテキスト・ロゴ・顔・テクスチャをカバーする自動劣化+グラウンドトゥルース復元パイプラインで構築されています。
2種類のリファインメントモードにわたる30,000のトレーニングサンプル:
入力画像 + 対象オブジェクト・テキスト・顔の参照画像 → 参照に合わせて領域を復元する。
入力画像 + テキストプロンプトのみ → テキスト記述だけに基づいて領域を復元する。
Sections 4 – 5
4–5. 実験
RefineAnythingは、領域特定画像リファインメントの初の専用ベンチマークRefineEvalで評価されます。参照ベースと参照なしの両設定で、FLUX Kontext・SDEdit・InstructPix2Pixなどの最先端ベースラインと比較されます。
参照ベースのリファインメント
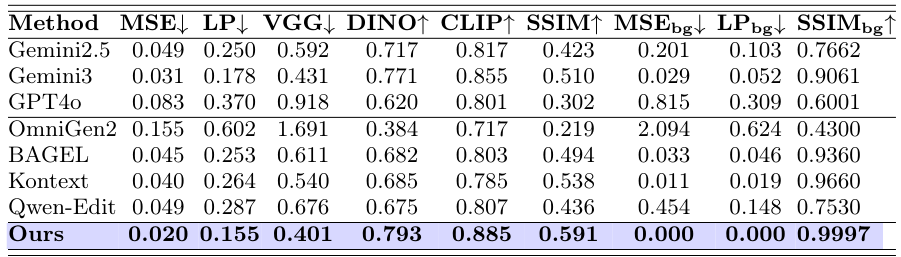
表1:RefineEvalにおける定量的結果(参照ベース設定)。評価指標:CLIP-I(参照忠実度)・PSNR・SSIM(境界保持)・複合忠実度スコア。RefineAnythingはすべての指標で最高スコアを達成します。
定量的な改善に加え、以下の定性比較でRefineAnythingの優位性が明確です。ベースラインモデルは読めるテキストの復元・ロゴの精確な描画・顔の特徴の保持に失敗しています。RefineAnythingは、精細なローカル詳細を復元しながら周囲の画像にシームレスに統合します。
参照なしのリファインメント
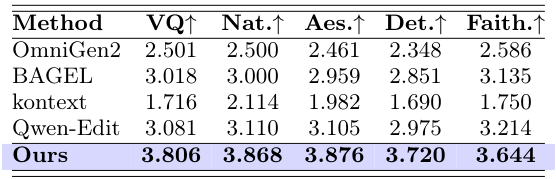
表2:RefineEvalにおける定量的結果(参照なし設定)。評価指標は指示追従・領域品質・背景保持をカバーします。RefineAnythingはすべてのプロンプトベースベースラインを上回ります。

実世界への応用結果
実用的な有用性を示すため、RefineAnythingをフロンティアモデル(GPT-Image・Gemini)が生成した画像に適用します。これらの画像には、製品上の誤ったテキスト・ぼやけた顔・不明確なロゴなど、典型的なローカル詳細の問題が含まれています。RefineAnythingは、指定された領域内のこれらの問題を周囲の画像を変えずに修正します。

Section 5.6
5.6 アブレーション研究
アブレーション研究では、各設計選択を1つずつ取り除き、RefineEval上の性能低下を測定することで各コンポーネントの貢献を検証します。
VAEボトルネックを解決
クロップ・アップサンプリングステップを除去するとぼやけた出力になります。フル解像度のビューがなければ、VAEエンコーダは小さな領域の細部を失います——RefineAnythingが解決しようとしたまさにその問題です。
シームレスな統合を実現
BCLを除去すると、領域境界に目に見えるシームが発生します——精製されたコンテンツが周囲の画像に溶け込めなくなります。BCLはペーストバックを知覚できないものにするために不可欠です。
セマンティックな誘導を提供
Qwen2.5-VLコンディショニングトークンを除去すると、精製された領域に誤ったコンテンツが現れます。VLMは「領域がどう見えるべきか」をエンコードし、それがなければ拡散モデルにセマンティックなアンカーがありません。

表3:アブレーション研究の定量的結果。各コンポーネント(Focus-and-Refine・Boundary Consistency Loss・VLMコンディショニング)を除去するといずれも性能が有意に低下し、3つの設計選択すべての妥当性が検証されます。


Section 6
6. おわりに
RefineAnythingは領域特定画像リファインメントを専用の研究問題として定義し、それに対する初の実用的なシステムを提供します。Focus-and-Refineはローカル詳細崩壊を引き起こすVAE解像度ボトルネックを解決します。Boundary Consistency Lossは精製された領域のシームレスな統合を実現します。Refine-30KとRefineEvalは研究コミュニティに必要なトレーニングと評価のインフラを提供します。
RefineEvalの結果は、参照ベースと参照なしの両設定において、テキスト・ロゴ・顔の詳細回復にわたってすべてのベースラインを一貫して上回ります。フロンティアの画像生成モデル(GPT-Image・Gemini)が全体的な品質を向上させる中、領域特定リファインメントはローカル詳細のギャップを埋め、真に制作使用可能なAI生成画像を実現します。
参考文献(クリックして展開)
- Rombach et al. High-Resolution Image Synthesis with Latent Diffusion Models. CVPR 2022.
- Black Forest Labs. FLUX. 2024. https://blackforestlabs.ai/
- OpenAI. GPT-Image-1. 2025.
- Google DeepMind. Gemini Image Generation. 2025.
- Brooks et al. InstructPix2Pix: Learning to Follow Image Editing Instructions. CVPR 2023.
- Meng et al. SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations. ICLR 2022.
- Bai et al. Qwen2.5-VL Technical Report. 2025.
- Zhou et al. RefineAnything: Multimodal Region-Specific Refinement for Perfect Local Details. arXiv:2604.06870, 2026.