FORGE ベンチマーク
データセット概要
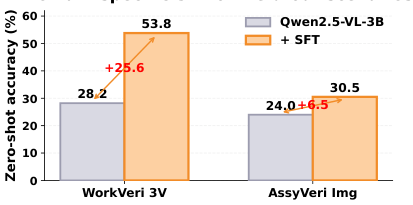
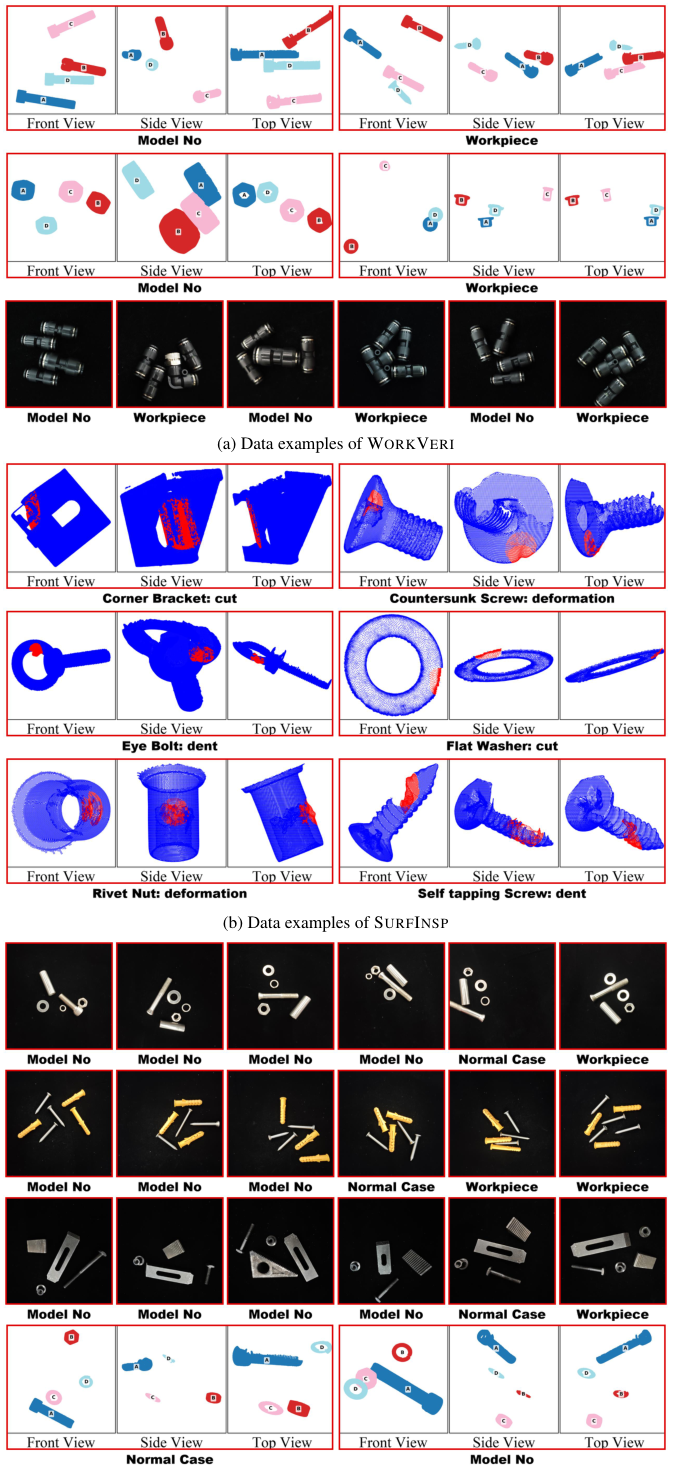
FORGE にはボルト・ネジ・ブラケット・ギア・組立品など多様な製造ワークピースにわたる 12,972 件のサンプルが含まれています。各サンプルは同一の実物部品から撮影した 2D 画像と 3D 点群を組み合わせており、異なるスケールとモダリティで相補的な視覚情報をモデルに提供します。
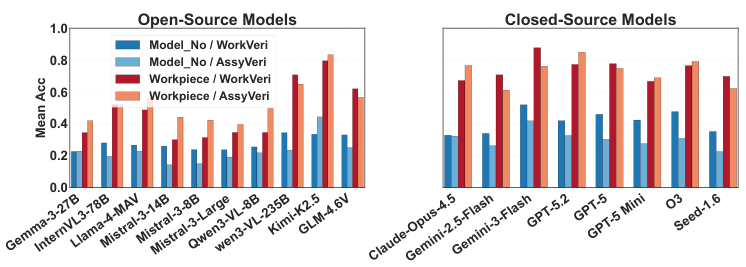
決定的な違いは、アノテーションが粗いカテゴリを超えていることです。各サンプルにはワークピースの正確な型番——製造品質管理が実際に依存している細粒度な識別子——がラベル付けされています。これが FORGE をすべての先行ベンチマークと区別する特性であり、現在の MLLM のドメイン知識ギャップを明らかにする要因です。
3 つの製造タスク
FORGE は製造品質管理における中核的な認知課題を反映した 3 つのタスクを定義しています。各タスクは視覚的知覚・言語的推論能力の異なる組み合わせを必要とします:
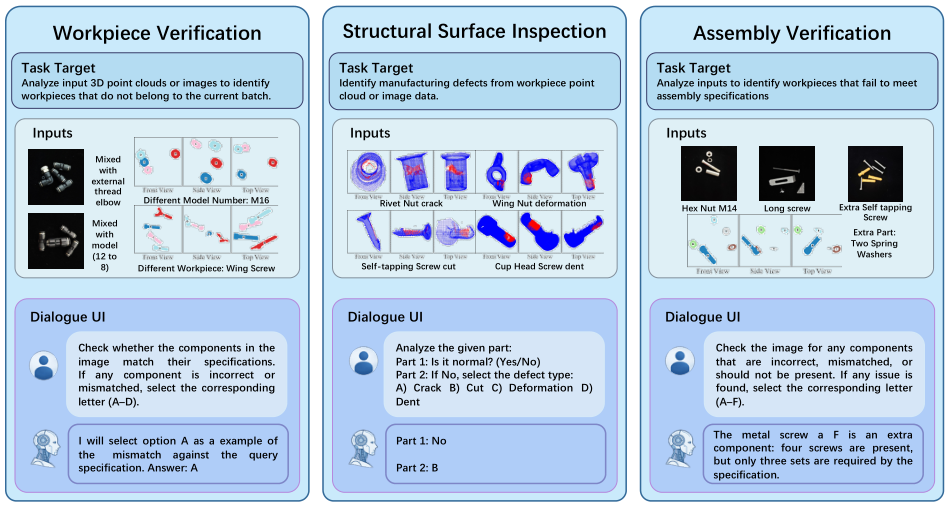
ワークピース検証(WORKVERI)
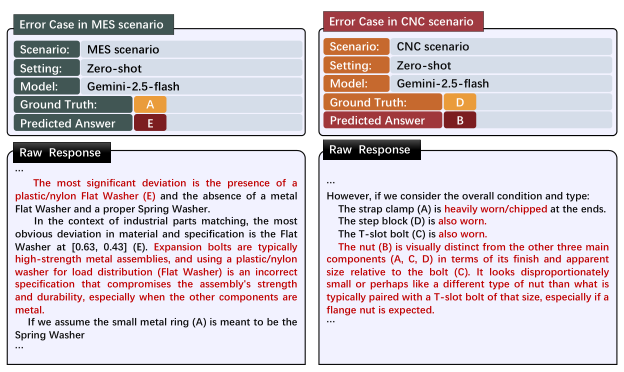
ワークピースの 3 方向画像から欠陥の有無と欠陥タイプを判定します。特定の部品種別に対する欠陥形態の細粒度な理解とドメイン知識をテストします。
構造表面検査(SURFINSP)
2D 画像からミクロスケールの表面欠陥(亀裂・凹み・腐食)を検出します。最も難易度の高いタスクであり、熟練した人間の検査員でも課題となる微妙な視覚的異常の検出が求められます。
組立確認(ASSYVERI)
複数の部品が正しく組み立てられているかを判定します。部品の関係性に関する空間推論と、部品がどのように組み合わさるべきかの理解が必要です。
評価設定
FORGE は 4 つの設定で MLLM を評価します:ゼロショット(標準的な単一画像)、参照条件付き(Ref-Cond)(正常部品の参照画像を提供)、文脈内デモンストレーション(ICD)(少数ショット例示)、3 方向視点(3V)(3D スキャナによるマルチアングル画像)。
2 つの入力粒度レベルでテストします:モデルレベル(正確な型番の識別)とワークピースレベル(部品カテゴリのみの識別)。この 2 レベル間のギャップが細粒度認識の難易度を定量化します。