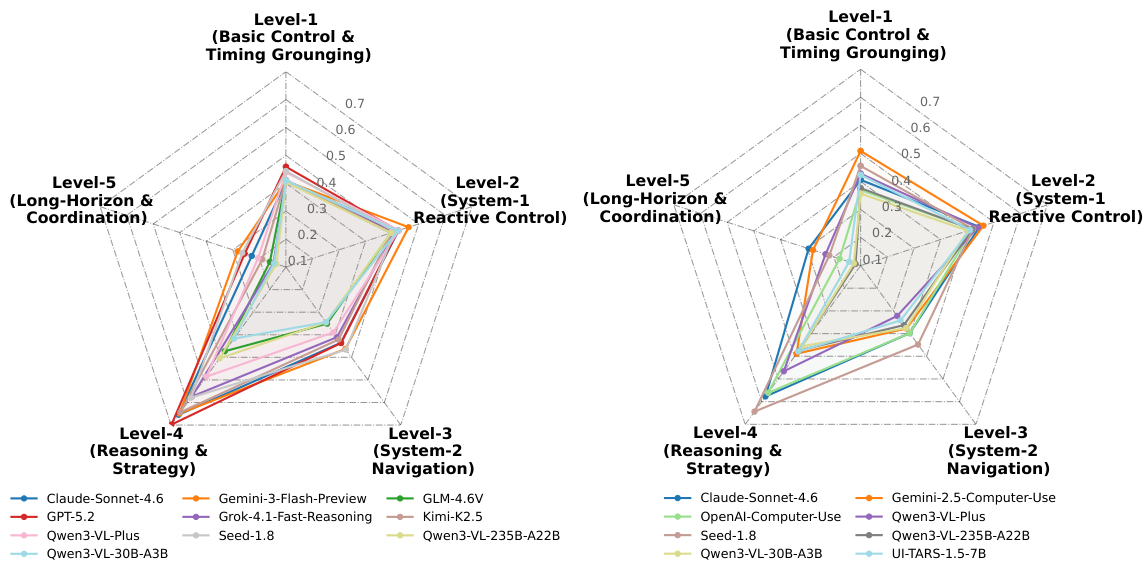
ゲームエージェントインターフェース
GameWorldでは、ゲームエージェントを制御するための2つの異なるアプローチを研究しています。各ステップにおいて、エージェントは現在のゲームの状態のスクリーンショットを観察し、モデルを通じてアクションを生成し、そのアクションが環境によって実行されます。その後、検証可能な評価器が、結果の状態をタスクの目標と比較します。
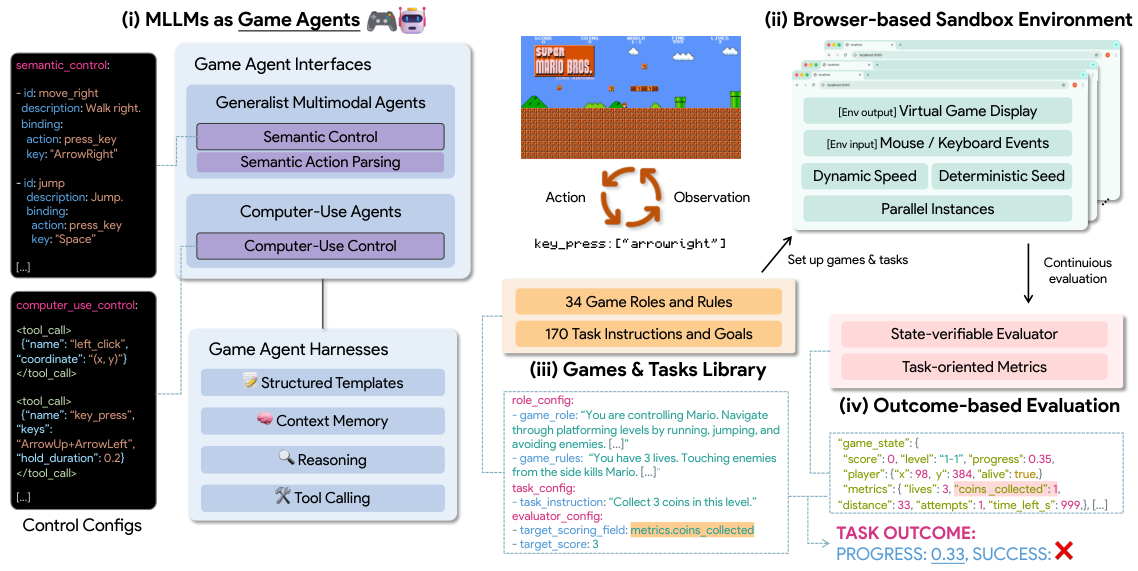
コンピュータ利用支援エージェント (Computer-Use Agent, CUA)
低レベルのキーボードおよびマウス操作を直接実行し、まるで人間がコンピュータを操作しているかのように動作します。このモデルは、ゲームの理解に基づいて、正確な物理的な入力を生成する必要があります。
- 操作: マウスクリック、スクロール、キー入力、ドラッグ、テキスト入力
- UI要素をピクセルレベルで理解する必要がある。
- より一般的なが、ゲーム固有のタスクには適していない場合があります。
汎用エージェント (GEN)
セマンティックな、ゲーム固有の関数呼び出し(例:`move_forward()`, `action_jump()`)を使用します。アクションは、セマンティック・アクション・パーシングによって、決定論的に低レベルのコントロールに変換されます。
- アクション:ゲーム固有のセマンティック関数。例:`
move_right()`、`weapon_fire()` - セマンティックアクションは、決定論的にコントロールにマッピングされます。
- ゲームタスクにおいては、より正確な結果を得られますが、アクション空間の定義が必要となります。