2. 方法:SkillClawの仕組み
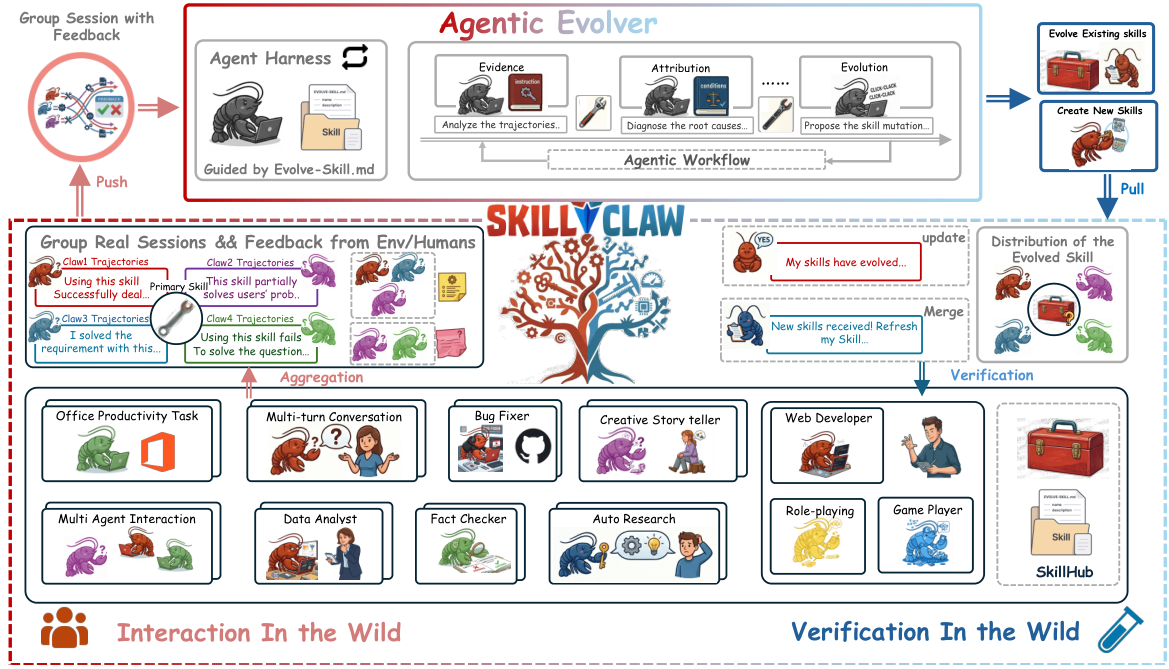
3段階の進化パイプライン
証拠収集
マルチユーザーエージェントは、実際のタスク中にセッションの軌跡を生成します。各軌跡は、アクションとフィードバックの因果関係を完全に捉えています。これらの軌跡は、すべてのユーザーから継続的に収集され、共有されたエビデンスプールに統合され、それが「Evolver」に供給されます。
エージェント的進化論 (Agentic Evolver)
3段階の自律型パイプライン:Evidence(再発パターンとエラーの兆候を分析)→ Attribution(根本原因の診断:スキル問題か、エージェントの問題か)→ Evolution(特定のスキル改善策を提案)。人間の介入なしで動作します。
スキル同期
更新されたスキルは、共有のSkillHubリポジトリに保存され、すべてのエージェントに自動的に同期されます。あるユーザーの利用状況から得られた改善点は、システム全体に適用されます。この改善ループは、新しいセッションが蓄積されるにつれて、継続的に実行されます。
2.1 個別セッションから共有可能な証拠へ
従来のAgentシステムでは、各ユーザーセッションを独立したものとして扱います。つまり、あるユーザーの成功または失敗した操作に関する情報は、他のユーザーには伝わりません。SkillClawは、集中型のセッションデータストアを維持することで、この問題を解決します。Agentがスキルを実行するたびに、完全なアクションと観察の連鎖を捉えた構造化された軌跡が生成されます。これらの軌跡には、実行されたスキルと結果(成功、部分成功、失敗)がタグ付けされます。特定のスキルに関する十分なデータが蓄積されると、Agentic Evolverが起動され、パターンを分析します。
「セッション軌跡」とは?
「セッション軌跡」とは、あるユーザーがエージェントとやり取りした際に発生したすべての出来事の構造化された記録です。単に最終的な結果だけでなく、以下の完全なシーケンスが含まれます。(1) エージェントが決定した行動、(2) エージェントが呼び出したツールとその引数、(3) 環境からの返却値(成功、エラー、部分的な結果)、および(4) エージェントが各フィードバック信号にどのように反応したか。これは、エージェントのフライトデータレコーダーのようなものです。この行動 → フィードバック → 次の行動という因果関係は非常に重要です。なぜなら、これはスキルがどこで、なぜ失敗したかを正確に示し、単に失敗したという事実だけを示すものではないからです。SkillClawは、これらの軌跡をすべてのユーザー間で集約し、繰り返し発生するパターンを特定します。
- 例: エージェントがポート9100でSlack APIを呼び出す → 接続拒否(エラー)→ エージェントがヒューリスティックな回避策を用いて再試行 → 部分的な成功。この軌跡は、スキル仕様におけるポート番号が間違っていることを示しています。
- なぜユーザー間の集約が必要なのか? あるユーザーの軌跡は、ノイズが多く、誤解を招く可能性があります。しかし、50人のユーザーがすべて同じステップで同じような失敗を示している場合、それは体系的なスキルのバグの強い兆候です。
2.2 エージェント能力進化アルゴリズム
Input: Skill set S = {s1,...,sn}, Session history H, SkillHub K
Repeat — runs continuously as new sessions arrive:
1. Extract trajectory batch B from session history H
2. Summarize sessions using LLM evolver → extract evidence signals
3. For each skill si ∈ S:
a. Analyze trajectories involving si (Evidence stage)
b. Attribute failures: skill-caused vs. agent-caused (Attribution stage)
c. If skill is the cause: propose update δ(si) (Evolution stage)
d. Apply update: si' = si + δ(si) [if improvement confirmed]
4. Push si' to SkillHub K; broadcast to all agents
Until terminated
帰属判定: Evolverはどのようにスキル失敗とエージェントの失敗を区別するのか?
これはシステムの中でも最も難しい部分であり、そしておそらく最も重要な部分です。すべての失敗がスキルのせいであるとは限りません。時には、エージェントが単純に不適切な推論を行い、タスクを誤解したり、完璧に機能するスキルを使用しているにもかかわらず、悪い決断を下したりすることがあります。 帰属判定段階は、次の問いを立てることでこの問題を解決しようとします: 「この失敗は、同じスキルを使用している複数のユーザー間で再現可能だったのか、それとも、この特定の*エージェント*の推論による単発的な問題だったのか?」
Evolverは、以下のような指標を使用します: (1) 複数のユーザーが同じスキルにおける同じステップで失敗したか? (2) エージェントの推論は、スキルの意図した経路から逸脱していたか? (3) スキルの仕様を変更することで失敗が解消されるか、それとも解消されないのか? もし失敗のパターンがユーザー全体で一貫しており、特定のスキルアクションに関連付けられている場合、それはスキルに起因すると判断されます。もし、失敗がエージェントによって大きく異なったり、特定のタスクのコンテキストに依存したりする場合、それはエージェントの推論に起因すると判断され、SkillClawはそれを変更しません。
2.3 スキルの同期と進化のサイクル
Agentic Evolverがスキルアップデートを提案すると、それはSkillHubにコミットされ、すべてのアクティブなエージェントインスタンスにプッシュされます。SkillClawは、新しいモードの同期戦略を使用します。エージェントは、アップデートを即座に(新しいモード)受信するか、安定したチェックポイントで受信するかを選択できます。この設計により、集団的に学習された改善が、進行中のセッションを中断することなく、すべてのユーザーに届きます。進化ループは常にアクティブであり、つまり、SkillClawは、エージェントが使用されている限り、スキルを継続的に改善します。

