方法論
正確性評価指標
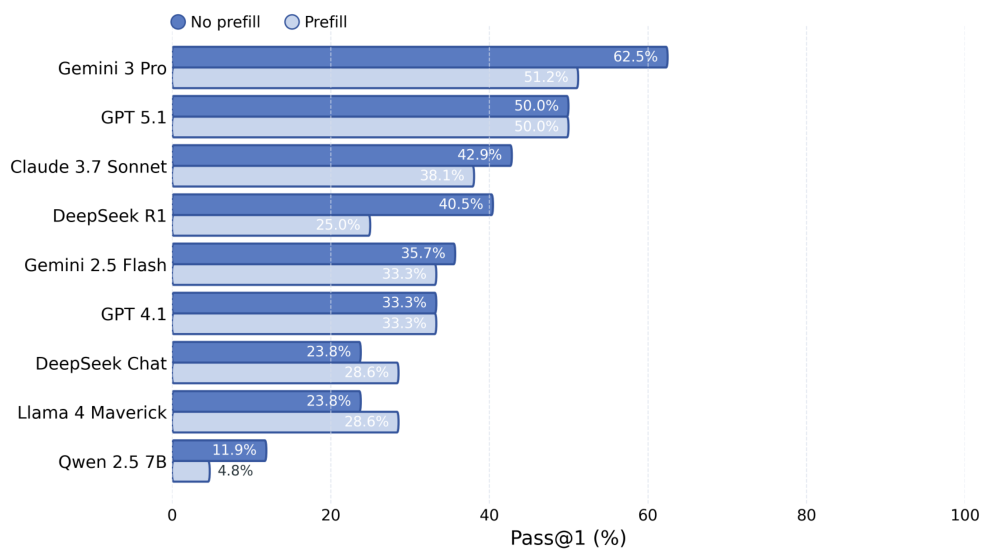
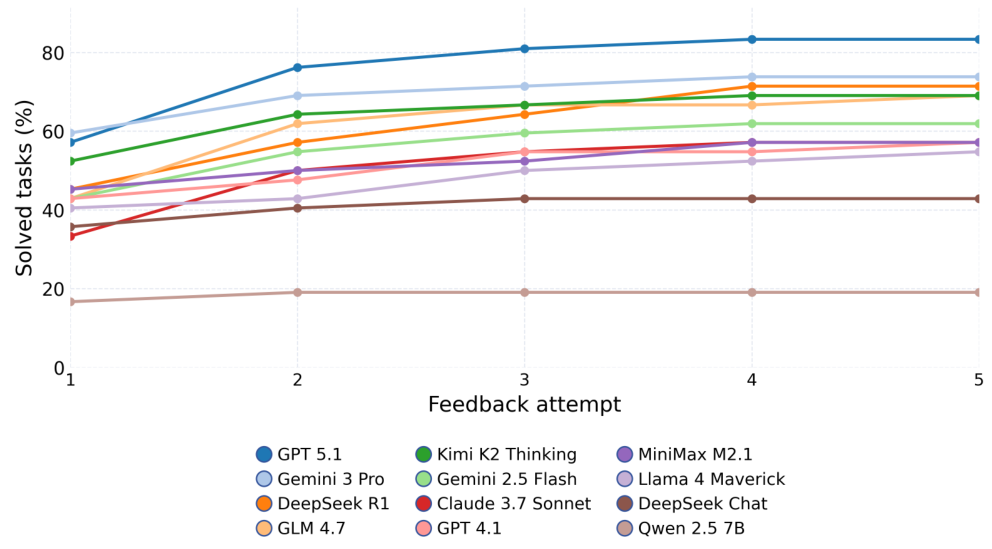
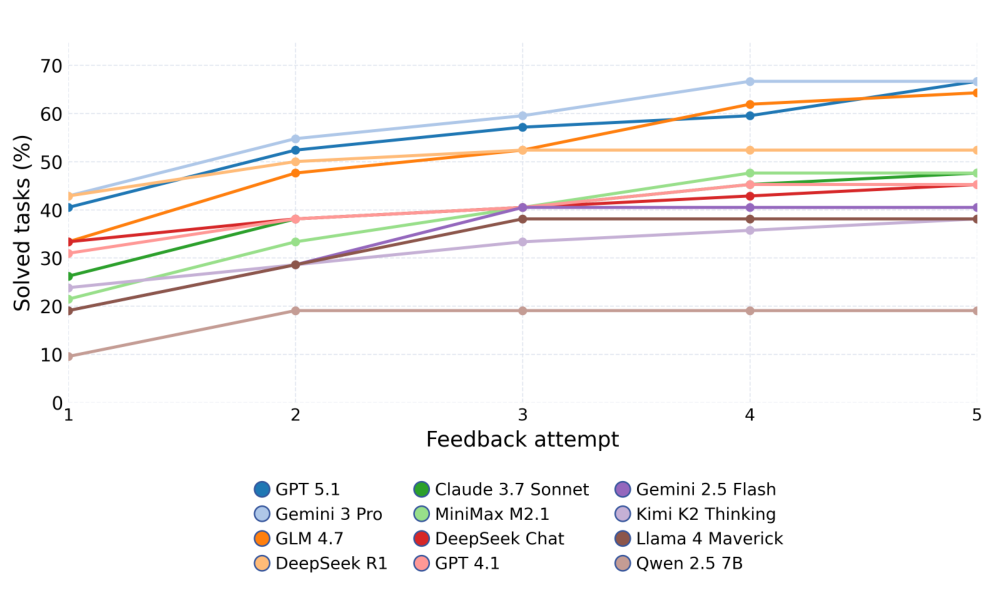
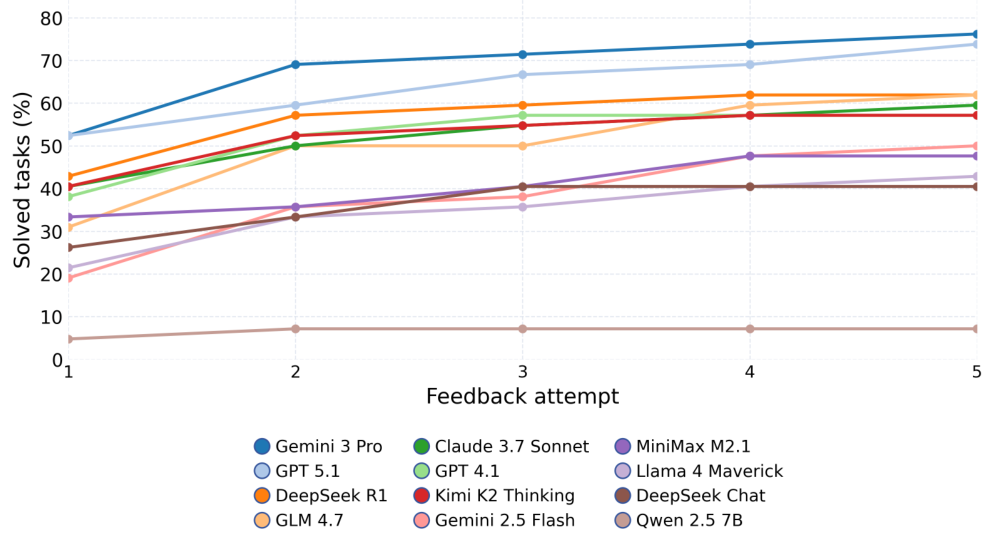
Pass@k は、機能的な正しさを評価する指標です。モデルは k 個のコードサンプルを生成し、そのうち少なくとも1つが正しい出力を生成した場合に合格となります。Pass@1 は、単一回の試行での精度をテストし、Pass@5 は、モデルに5回の試行回数を与えます。
KL-Divergence Acceptance は、確率的な量子出力を取り扱います。量子測定は本質的に確率的であるため、正確な出力の一致は機能しません。代わりに、QuanBench+ は、参照分布とモデルの出力分布との間の KL ダイバージェンス \(D_{KL}(P_{\text{ref}} \| P)\) を計算します。ダイバージェンスが閾値 \(\tau = 0.05\) (ヌル分布の 0.997 分位数で調整) を下回る場合、出力は受け入れられます。
KL-ダイバージェンスの平易な説明
KL-ダイバージェンスは、2つの確率分布がどれだけ異なるかを測る指標です。例えば、あるコインが表が出る確率が60%であるとします。もしモデルの量子プログラムが表が出る確率を58%にした場合、KL-ダイバージェンスは非常に小さく(一致度が高い)、良い結果です。しかし、表が出る確率が90%の場合、KL-ダイバージェンスは大きくなり(一致度が低い)、良い結果ではありません。QuanBench+では、0.05ナッツの閾値を使用しており、その差がこのレベルを下回る場合、出力は正しいと見なされます。この閾値は慎重に調整されており、たとえ全く同じ正しいプログラムを2回実行しても、サンプリングノイズによりわずかな違いが生じる可能性があります。その自然な変動範囲をわずかに上回る位置にこの閾値が設定されています。
なぜ忠実度ではないのか? 状態忠実度(state fidelity)は、完全な量子状態ベクトルへのアクセスを必要としますが、これは実際の量子ハードウェアでは利用できません。QuanBench+は、意図的に実際の量子デバイスでも機能する、測定に基づく正確性の基準を使用しています。

タスクのカテゴリ
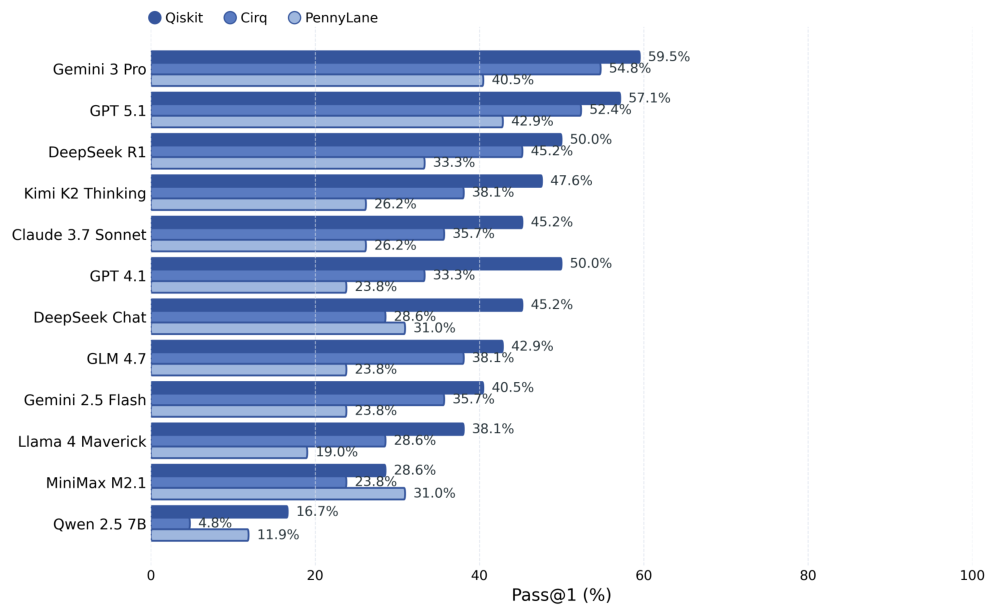
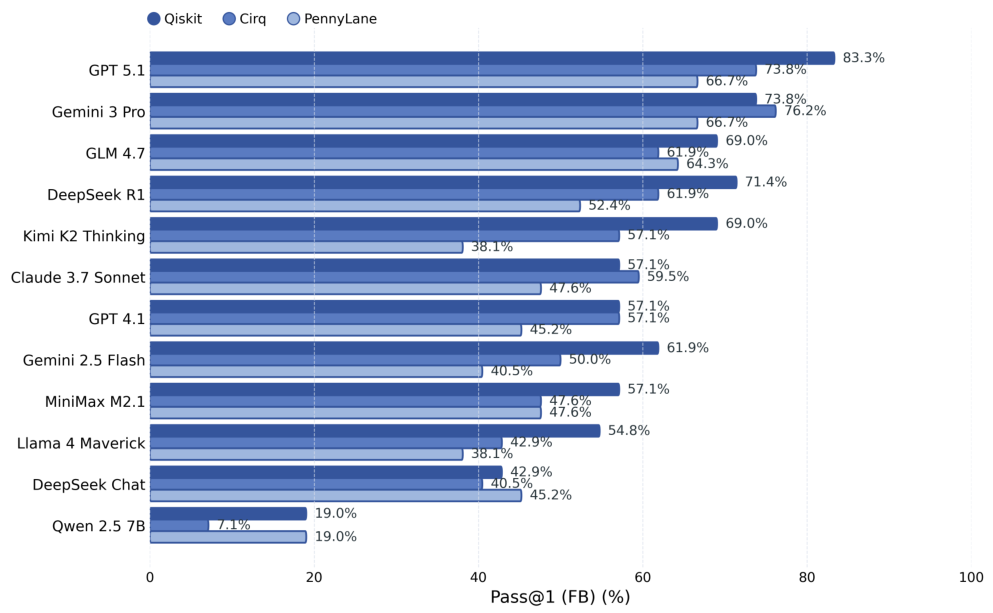
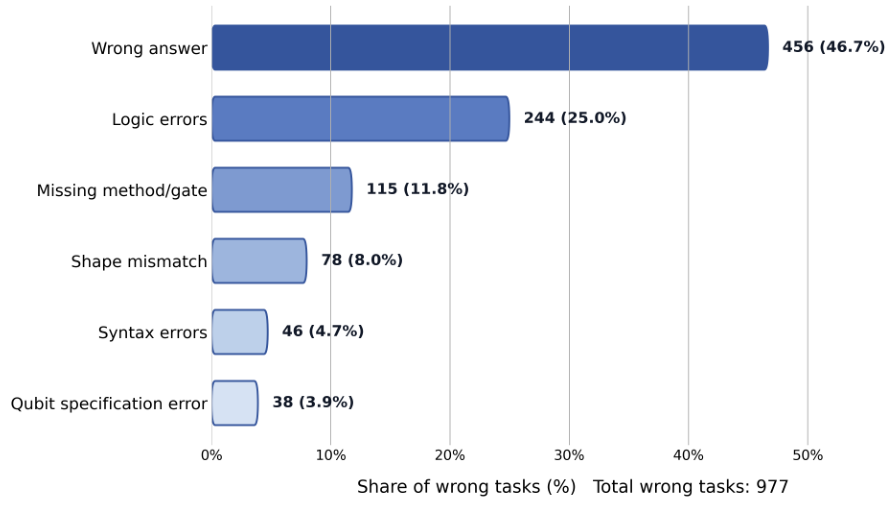
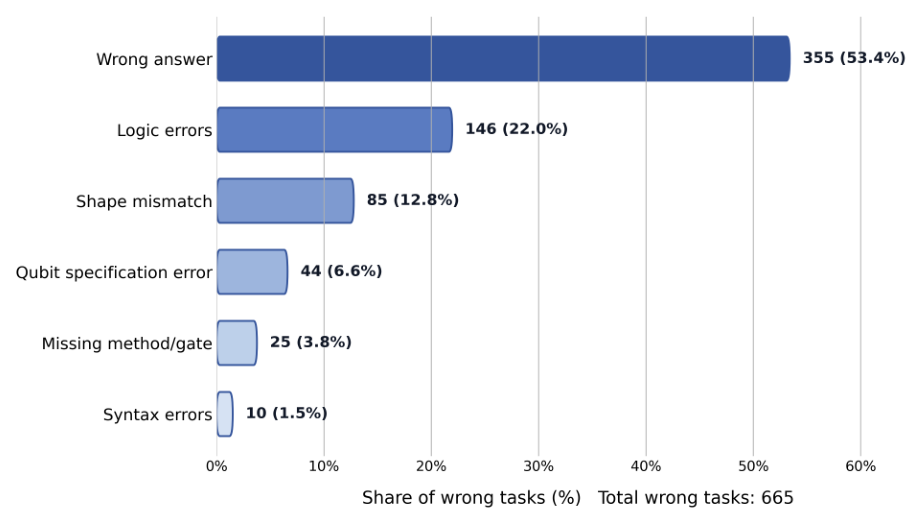
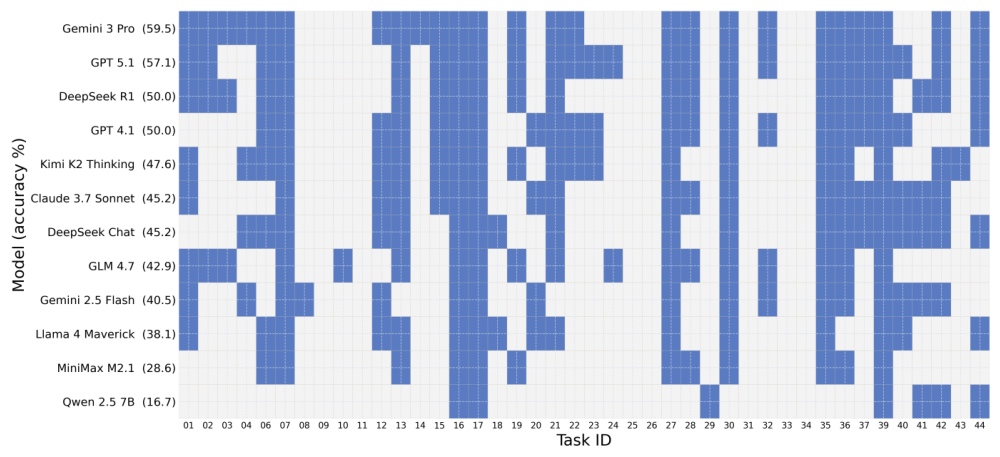
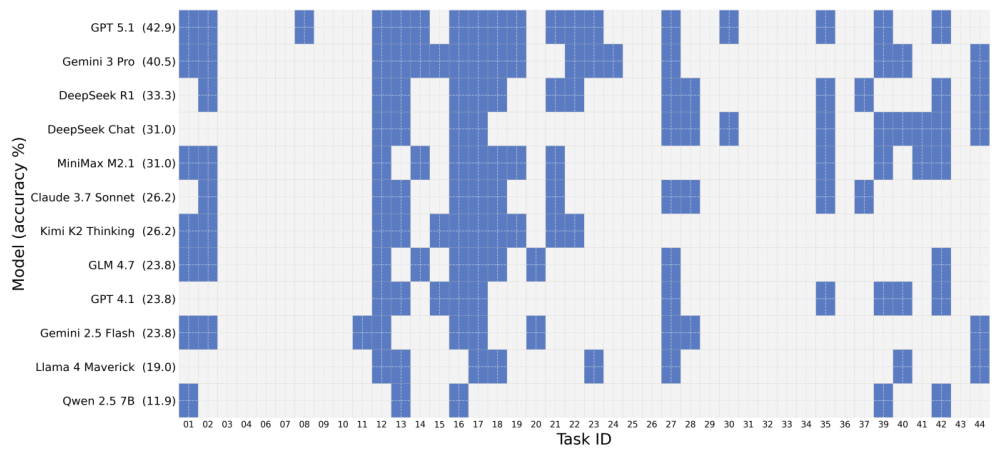
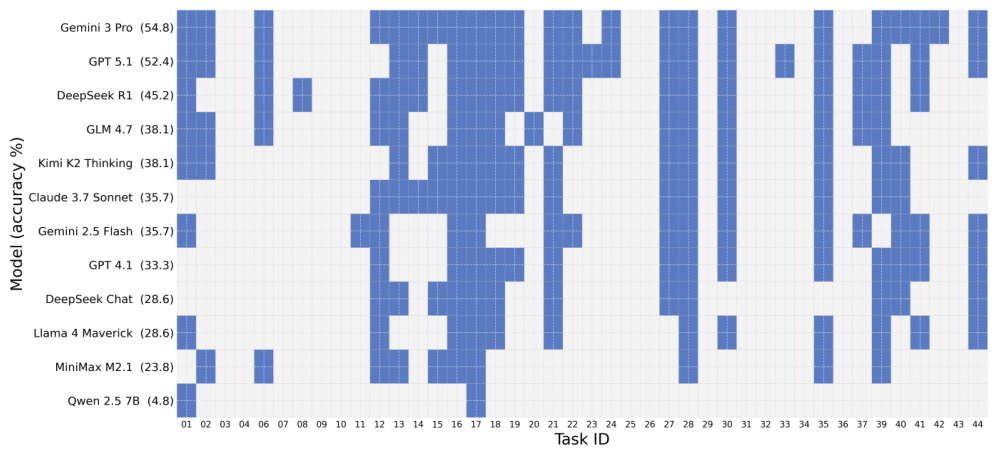
Qiskit、PennyLane、およびCirqの42個すべてのタスクは、標準化されたプロンプトと出力正規化によって整合性が保たれています。タスクには、Groverの探索アルゴリズム、Shorのアルゴリズム、量子フーリエ変換、VQEなどの古典的なアルゴリズム、ゲート分解の課題、および量子状態準備の問題が含まれます。各タスクは、決定的なシード制御を備えた、隔離されたサンドボックス環境で評価されます。