01
はじめに
物体を3Dで理解することは、空間認識の根幹をなします。エージェントが物理世界を確実にナビゲート・操作・推論するには、物体が何であるかを知るだけでは不十分で——物体がどこにあるか、どれくらいの大きさか、そして3D空間でどのような向きをしているかも把握しなければなりません。この能力こそが、ロボティクス・身体化AI・自動運転・AR/VRの中核にあるもので、これらの分野では精密な空間認識が成否を左右します。
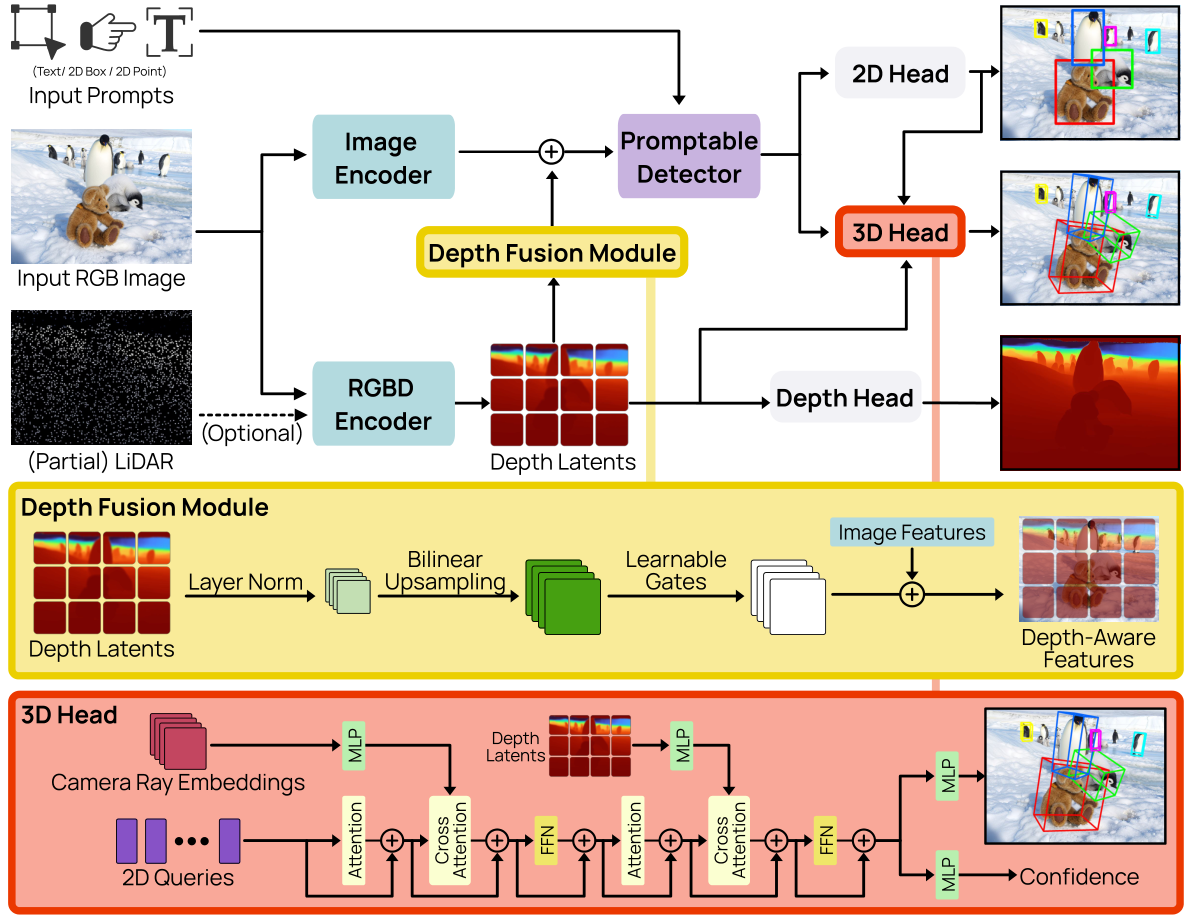
汎用単眼3D検出器に求められる3つの要件
- 実世界での汎化 — 物体カテゴリはロングテールで際限なく広がり、学習時に未見のものも多数存在します。
- 複数プロンプト形式のサポート — テキストクエリ、2Dポイントクリック、2Dバウンディングボックス、視覚的サンプル例への対応。
- オプションの深度情報の活用 — LiDAR・ステレオカメラ・ToFセンサーから得られる部分的または完全な深度マップが利用できる場合に組み込みます。
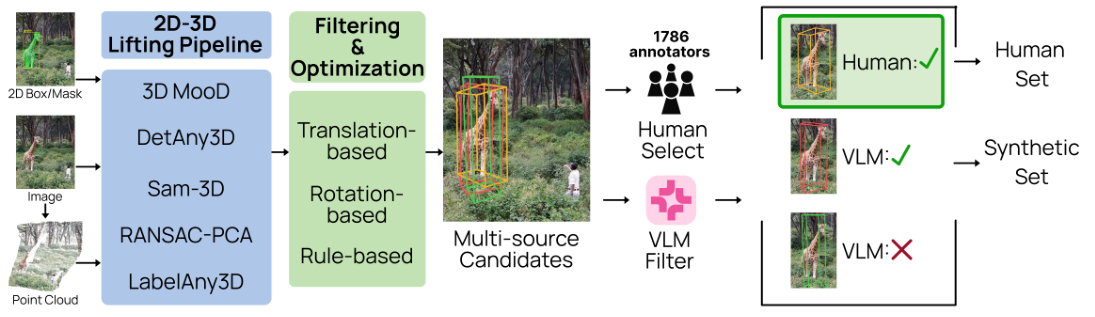
既存手法はこの3つの要件を同時に満たせません——クローズドセットのカテゴリのみ対応、単一プロンプト形式のみ、あるいは深度情報を無視するかのいずれかです。WildDet3Dは、統合された幾何学認識アーキテクチャと大規模実世界データセットによって、3つの要件すべてを満たします。
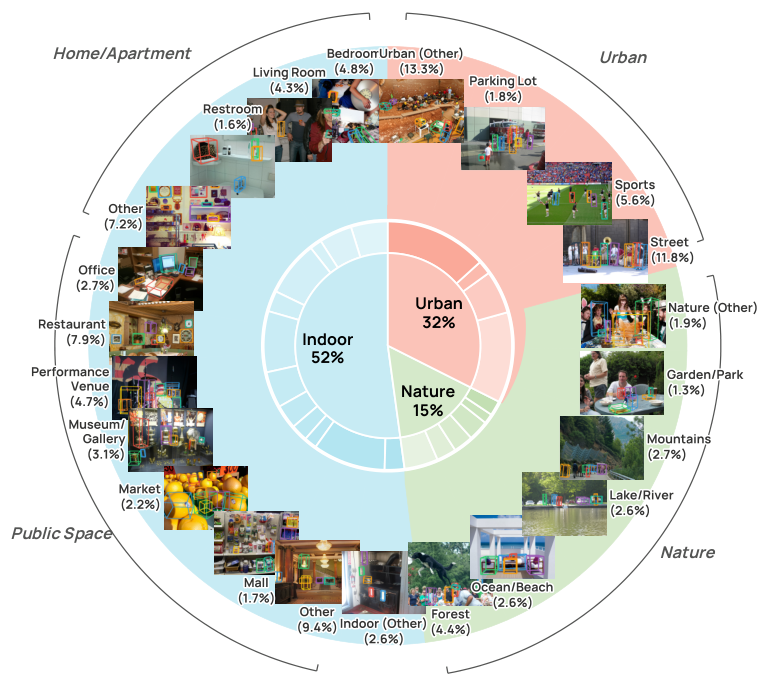
700カテゴリ以上のオープン語彙に対応した実世界ベンチマーク WildDet3D-Bench において、WildDet3Dはテキストプロンプトで 22.6 AP3D、ボックスプロンプトで 24.8 AP3D を達成しました。従来最良手法(3D-MOOD)の2.3 APと比べ、10倍の改善です。