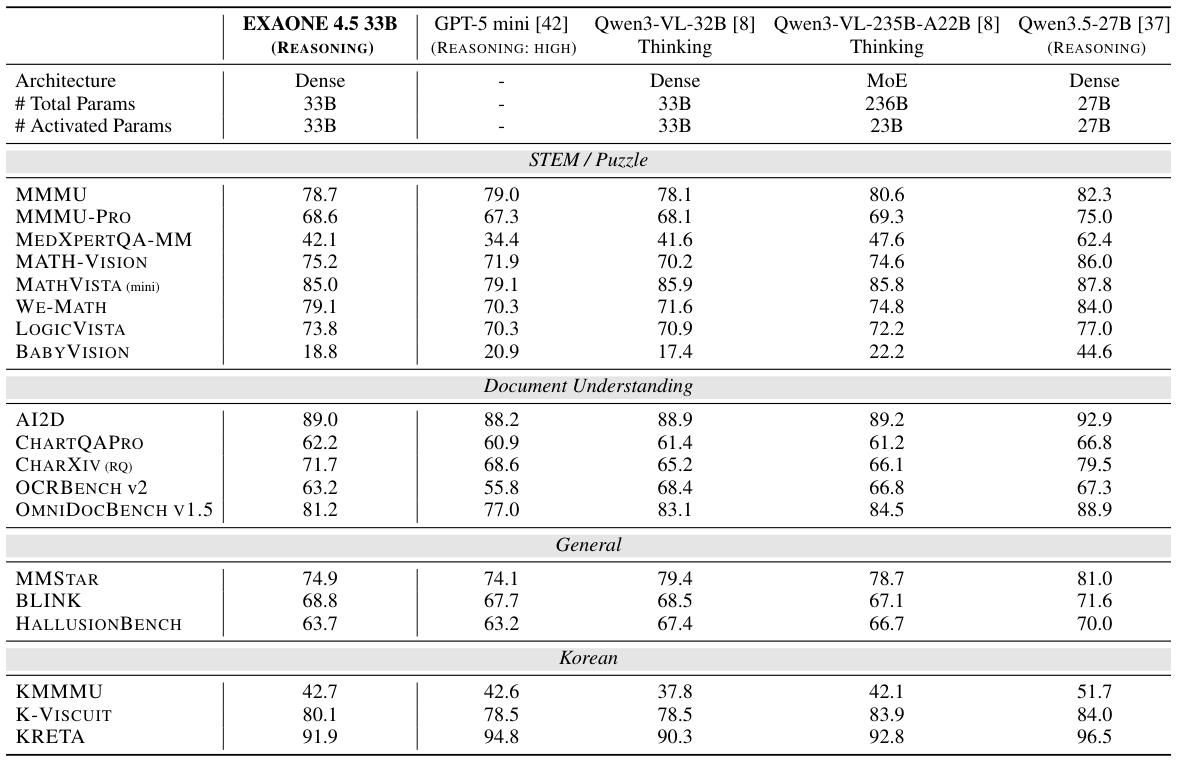
モデルのアーキテクチャとトレーニング
モデル構成
EXAONE 4.5は、画像とテキストを組み合わせたモデルにおける、主要な課題である、大量の視覚トークンとテキストを効率的に処理するという問題に対処します。計算効率を維持するために、開発チームはハイブリッドな注意機構と、ビジョンエンコーダー自体に適用されるグループクエリアテンション(GQA)を採用しました。これは革新的な選択であり、推論時のKVキャッシュメモリのフットプリントを大幅に削減します。このビジョンエンコーダーは、既存のエンコーダーがLGの拡張性と効率の要件を満たしていなかったため、1.2Bパラメータのモデルとしてゼロからトレーニングされました。また、このモデルは、画像をリサイズせずに、そのネイティブ解像度で処理するために、2Dロータリーポジショニング埋め込み(2D RoPE)を使用しており、文書理解において重要な空間関係を維持します。
GQA(グループクエリアテンション)とは?
従来のTransformerアテンションでは、各アテンションヘッドごとに個別のKey-Value (KV)キャッシュを保持する必要があります。これは、大規模モデルでは膨大なメモリを消費します。グループクエリアテンション(GQA)は、複数のクエリヘッドをまとめて、1つのKVキャッシュペアを共有することで、メモリ使用量を大幅に削減し、わずかな精度損失で実現します。
なぜこれはEXAONE 4.5にとって重要なのか? GQAをビジョンエンコーダに適用することは、非常に珍しく、革新的なアプローチです。画像は数千の視覚トークンを生成するため、KVキャッシュのサイズを小さく保つことは、実際のハードウェア上でモデルを効率的に実行するために不可欠です。
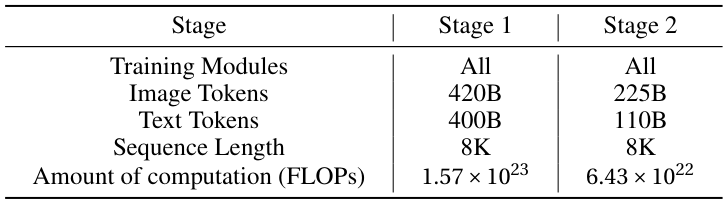
事前学習
マルチモーダル事前学習は、2つの段階で進められます。第1段階では、大規模な視覚-言語アライメントに焦点を当て、8Kのシーケンス長で、4200億個の画像トークンと4000億個のテキストトークンを用いて学習を行います。第2段階では、高品質なデータを用いて、より小規模なスケール(2250億個の画像トークン、1100億個のテキストトークン)で微調整を行います。この際、第1段階と比較して、FLOPsは6.43×10²²であり、第1段階の1.57×10²³よりも小さい値となります。事前学習に使用されるデータには、画像キャプション(韓国語-英語バイリンガル)、画像とテキストが交互に記述されたドキュメント、OCR/ドキュメントコーパス(LGのドキュメント中心のアプローチにとって重要)、および時間的な理解のためのビデオデータが含まれます。
トレーニングにおけるFLOPsの理解
FLOPs (浮動小数点演算) は、トレーニング中に使用される総計算量を測定します。ステージ1では1.57×10²³のFLOPsが必要となり、これは、単一の高性能GPUが約5,000年かけて計算するのに相当します。そのため、LLMのトレーニングには、数十台のGPUを並列で稼働させ、数週間かかるのです。
ステージ2のスケールダウン(6.43×10²² FLOPs)は、優れたベースモデルを改良するには、最初から構築するよりもはるかに少ない計算量で済むことを反映しています。
コンテキスト長拡張
EXAONE 4.5は、コンテキストのサイズを256Kトークンまで拡張します。これは、長さの拡張を、別個の事前学習段階としてではなく、教師ありのファインチューニング段階に直接統合することで実現されています。すでに128Kトークンの処理が可能なベースモデルを使用することで、安定性と高速な収束が実現されます。コンテキスト並列処理により、256Kの長さを持つシーケンスを複数のGPUに分散し、メモリ要件を管理可能な範囲に保ちます。これは、長文の法的文書、技術マニュアル、または複数ページの財務報告書など、産業用途における大規模なデータ処理において特に重要です。
なぜ256Kのコンテキストウィンドウが重要なのか?
多くの言語モデルは、4K~32Kトークンで制限されています。256Kのコンテキストウィンドウとは、モデルが一度に約200,000語を処理できることを意味します。これは、3~4冊の長編小説、またはすべての付録を含む長い法的契約書に相当します。
エンタープライズ向けドキュメントAIにとって、これは画期的なものです。金融アナリストは、完全な四半期報告書(注釈付き)を読み込ませることができます。法務チームは、完全な契約書を処理できます。エンジニアは、複数の章からなる技術マニュアルを理解できます。これらはすべて、テキストを分割したり、コンテキストを失ったりすることなく可能です。
トレーニング後
Supervised Fine-Tuning (SFT)
公的なデータセットだけに依存するのではなく、チームは、複数のドメインとモダリティをカバーする高品質なSFTデータセットを構築しました。これには、金融、法律、科学、および韓国語タスクに関するドメイン固有の指示データ、およびドキュメントQ&A、チャート理解、OCRタスクに関するマルチモーダルな指示データが含まれます。
Offline Preference Optimization
オフラインでの好みの最適化は、Direct Preference Optimization (DPO) を用いた多段階フレームワークで実行されます。各段階は、特定の能力を対象としています。具体的には、指示の理解、ドキュメントの理解、そして多言語対応です。DPOの損失関数は、参照モデルからの低品質な代替応答よりも、高品質な応答をモデルが優先するように促します。
Direct Preference Optimization (DPO) の解説
論文に記載されている DPO の式は複雑に見えますが、基本的な考え方はシンプルです。モデルが、応答のペアを比較することで、より良い回答を好むように学習させるというものです。
各トレーニングデータにおいて、モデルはプロンプト x、良い回答 y⁺(人間の評価者によって好まれる)、および悪い回答 y⁻(却下される)を見ます。モデルは、参照モデルと比較して、y⁺を生成する確率を高くし、y⁻を生成する確率を低くするように学習します。これにより、従来の RLHF とは異なり、別の報酬モデルを必要とせず、トレーニングをより安定させ、効率的に行うことができます。
Reinforcement Learning (RL)
ジョイントなマルチモーダル強化学習が、テキストとビジョンという両方のモダリティに適用されます。テキストデータは、数学的推論、コーディング、科学の問題を扱います。ビジョンデータは、図の理解、グラフに関する質疑応答、および文書解釈に焦点を当てています。強化学習は、モデルが様々な入力タイプに対して汎化する堅牢な推論能力を開発するのに役立ちます。