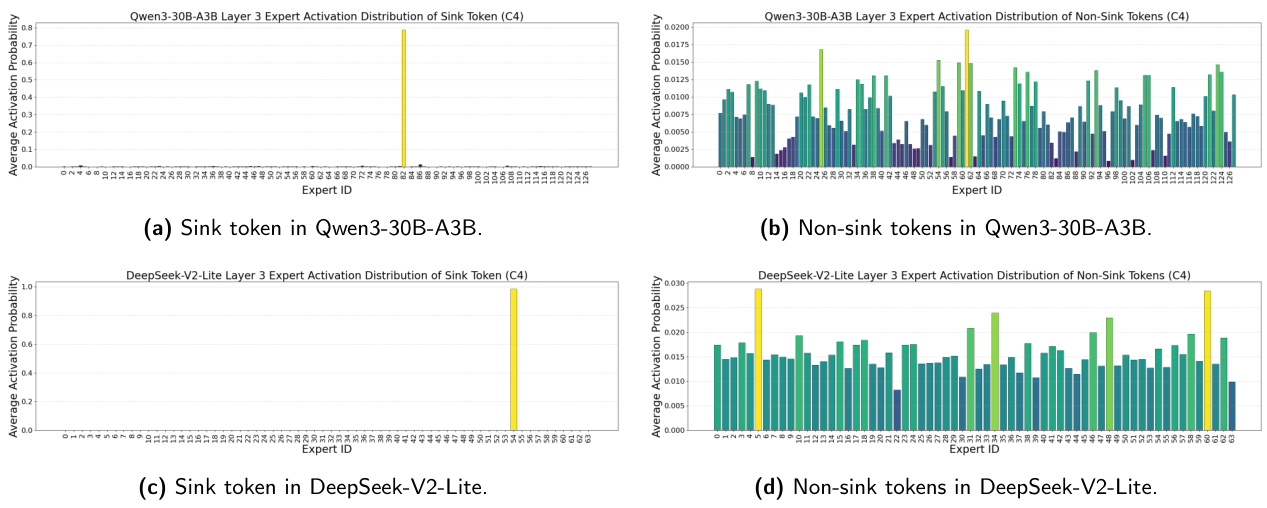
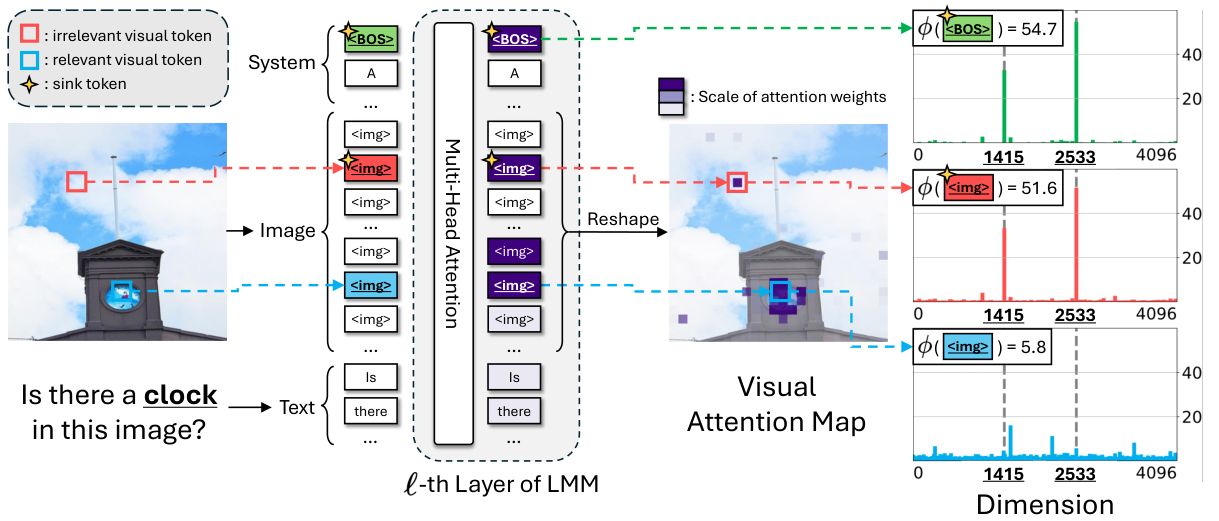
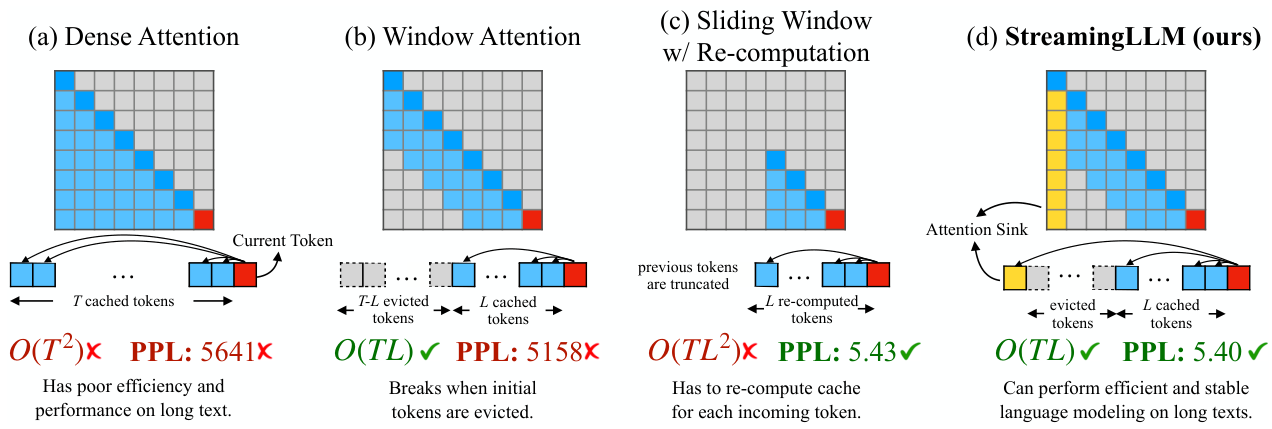
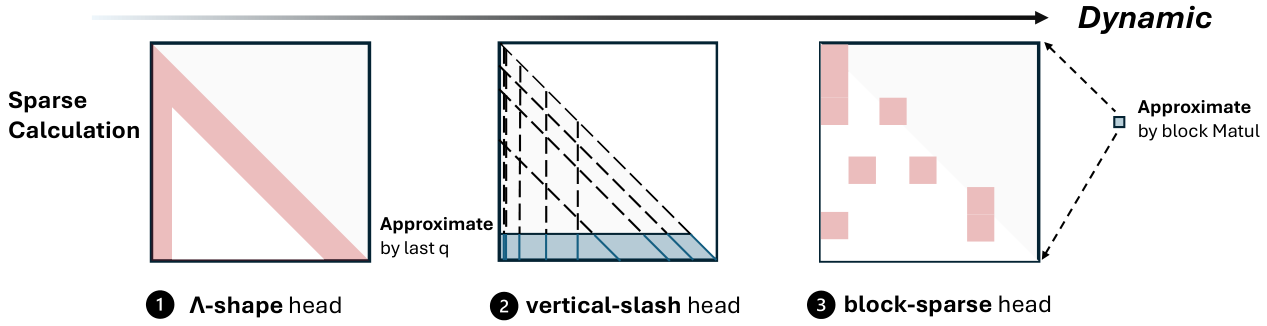
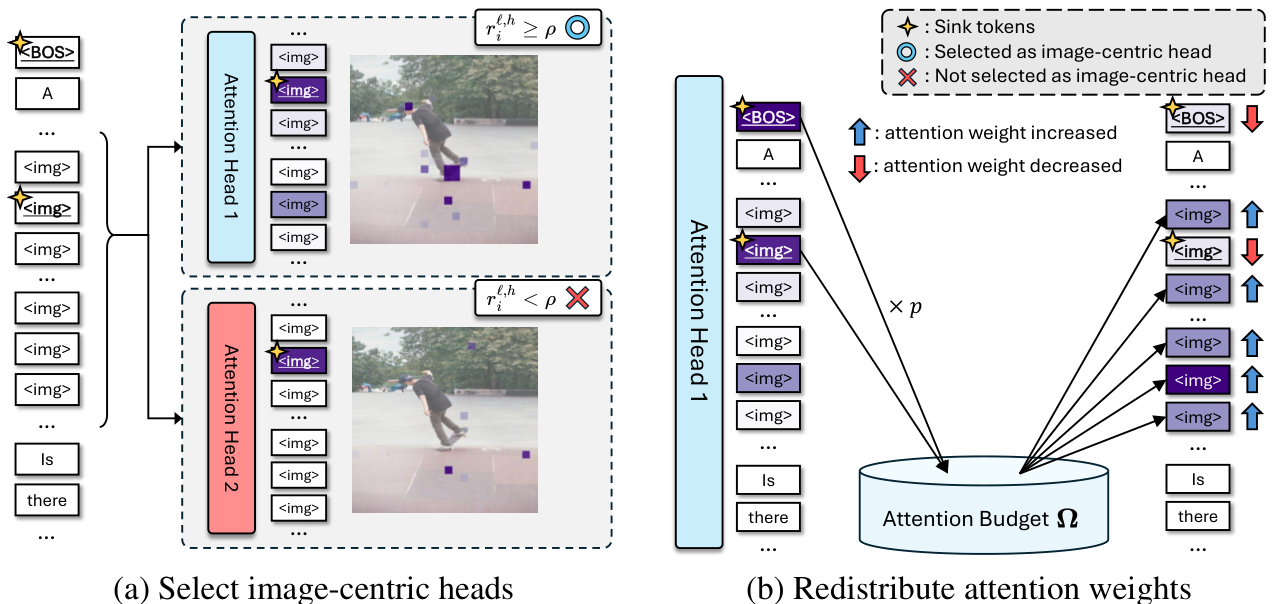
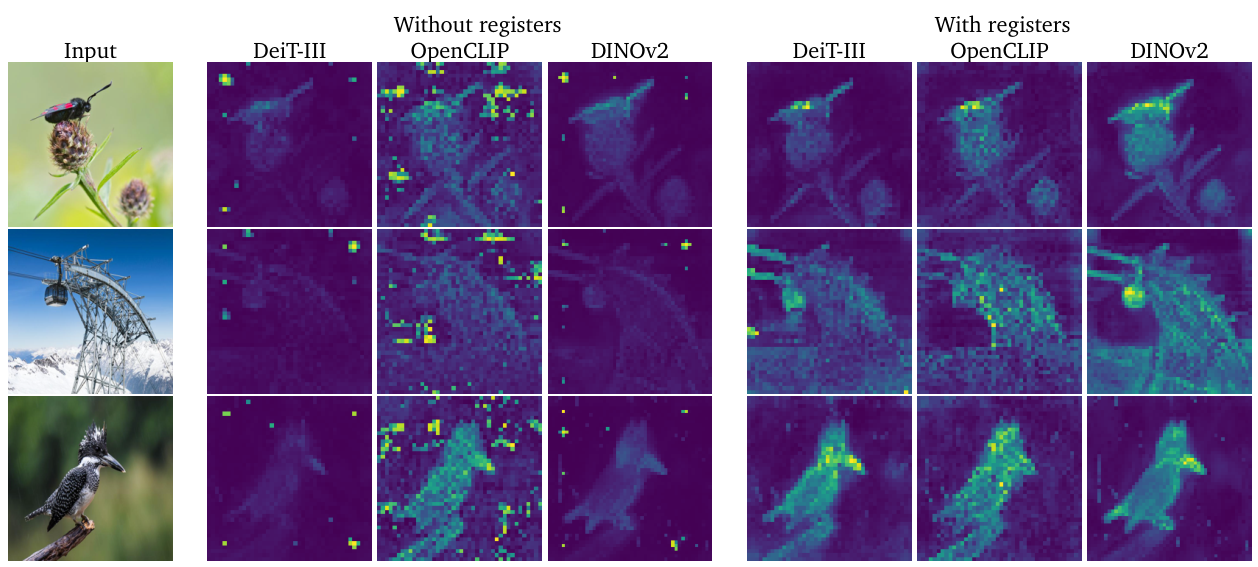
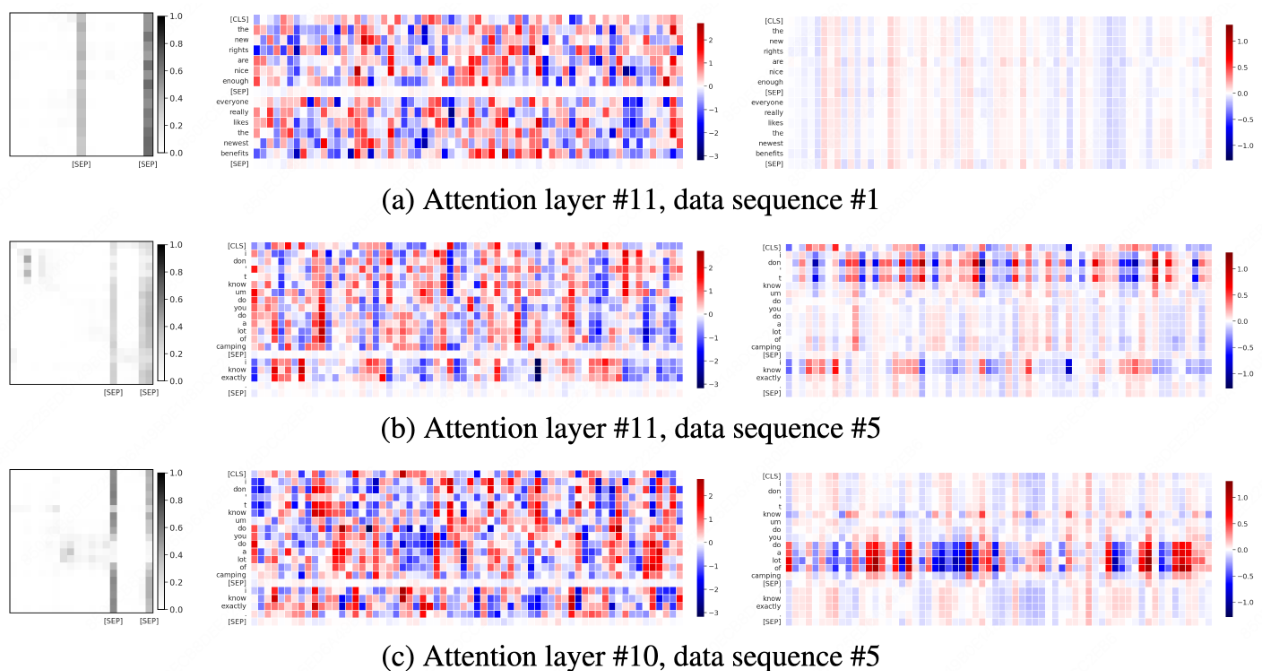
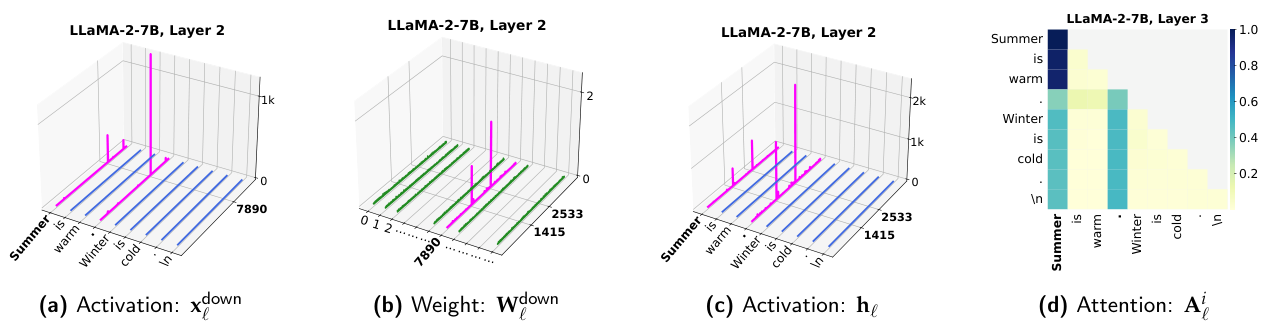
調査概要
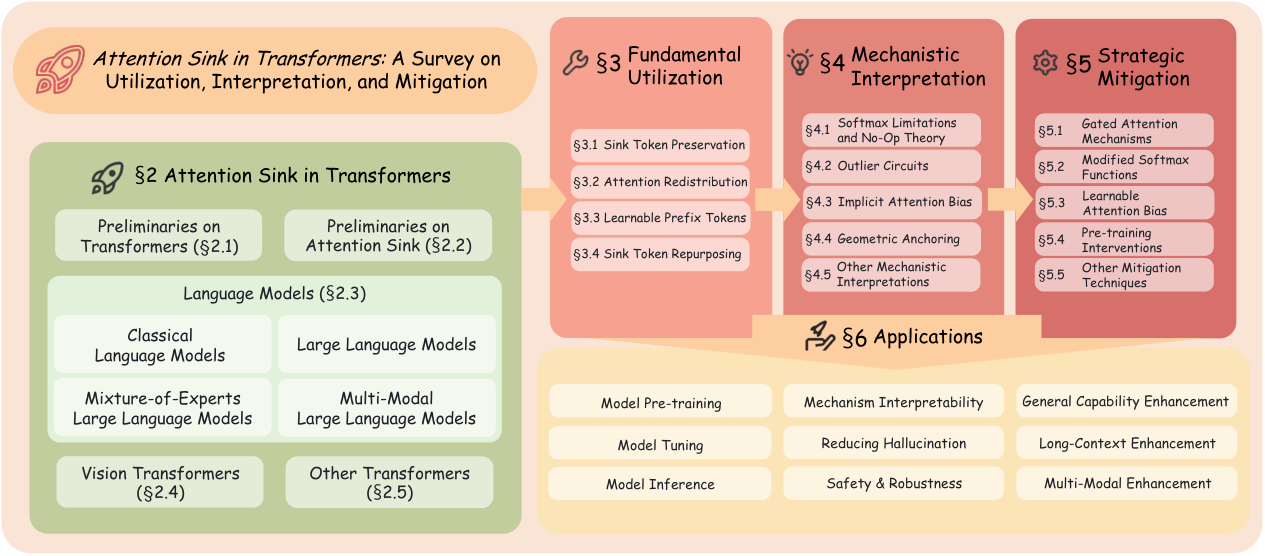
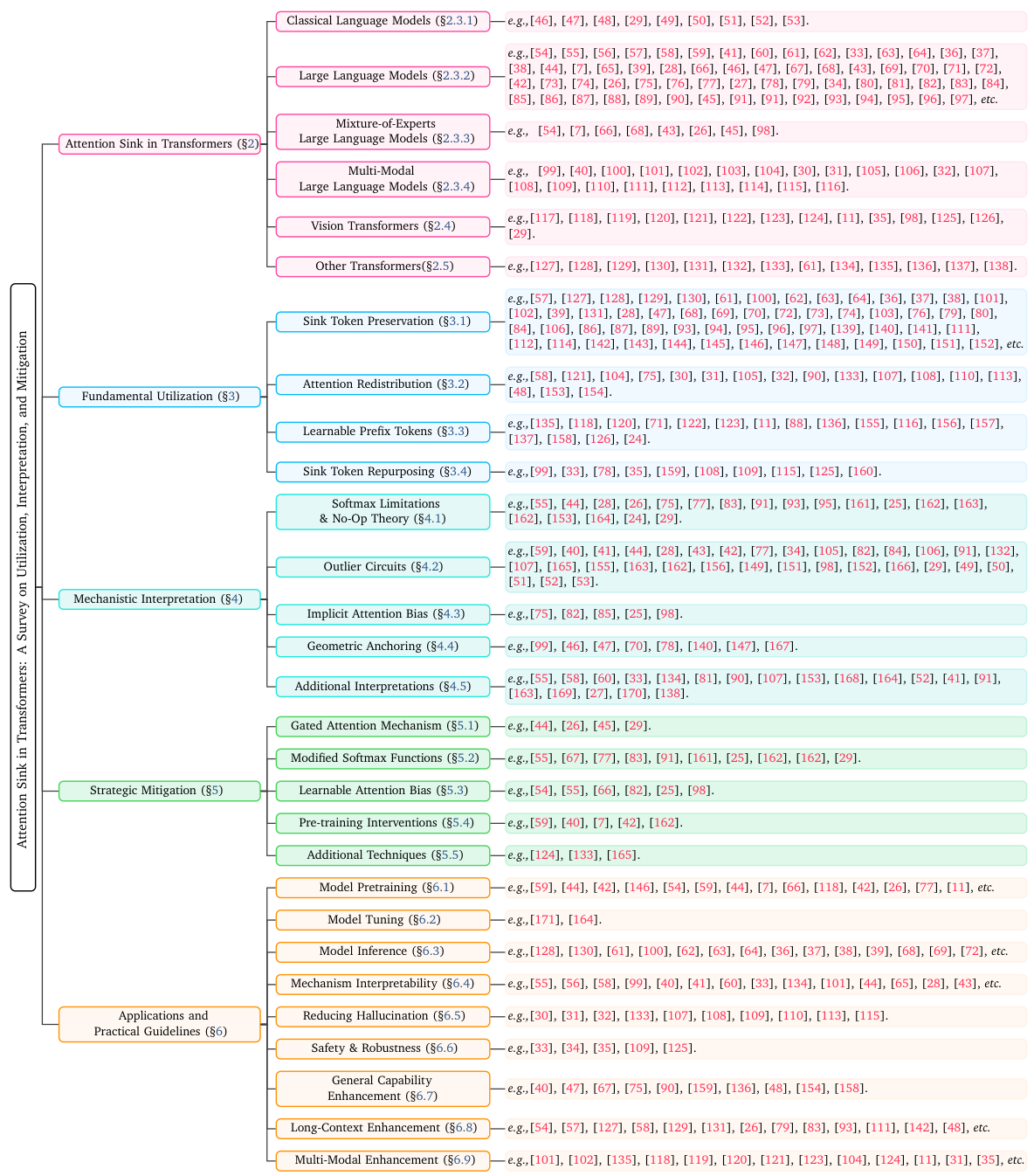
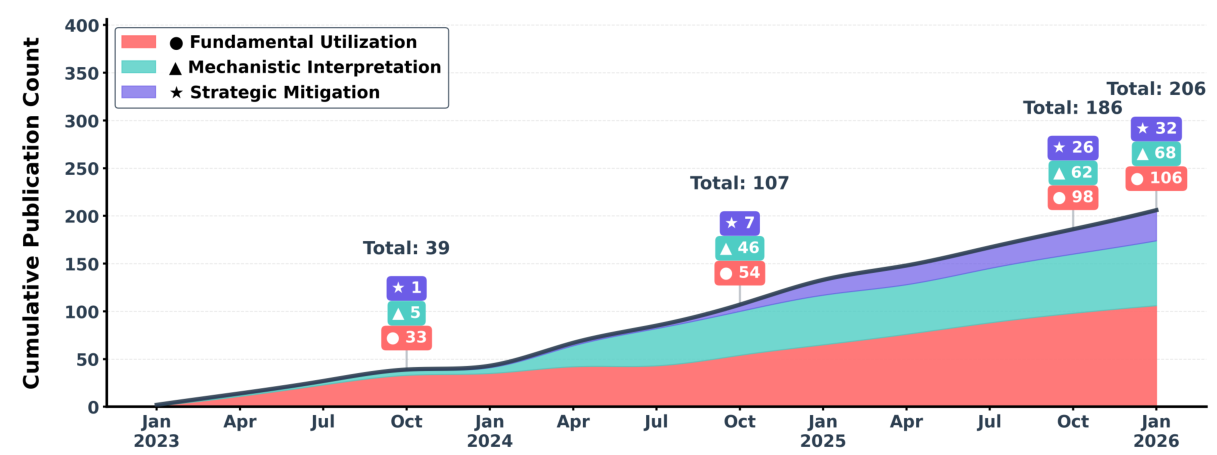
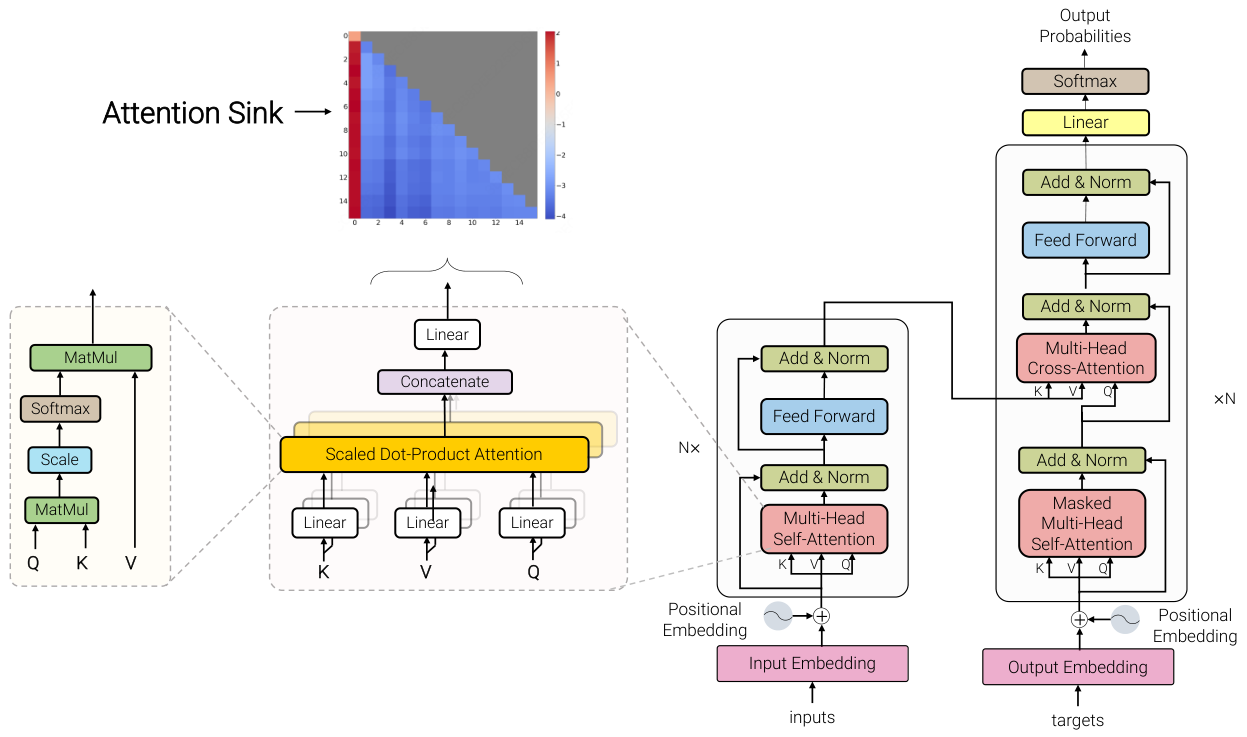
この調査は、Attention Sinkに関する研究を、明確な3つの柱を持つフレームワークに整理しています。 `基本利用 (Fundamental Utilization)` は、実務家がどのようにAttention Sinkのパターンを、効率的な推論のために活用するか(KVキャッシュ圧縮、スパースアテンションなど)を扱います。 `メカニズム解釈 (Mechanistic Interpretation)` は、softmaxの制約、外れ値回路、および幾何学的特性に関する理論を通じて、Attention Sinkがどのように発生するかを探求します。 `戦略的緩和 (Strategic Mitigation)` は、望ましくないアテンションの集中を減らすか、完全に排除するためのアーキテクチャの変更について説明します。