言語環境シミュレータ
OccuBenchの中核となる革新は、Language Environment Simulator (LES)です。LESは、LLM(大規模言語モデル)を活用してツール応答を生成し、特定の分野の環境をシミュレートする機能です。LESは、以下のように正式に定義されます。
get_patient_vitals(room_2) を呼び出すと、LESは、設定 c で定義されたルールに従って、心拍数、血圧などの妥当なJSON形式の応答を生成します。ここでは、c は環境設定(システムプロンプト、ツールスキーマ、初期状態、状態記述)であり、st はLLMのコンテキストウィンドウによって暗黙的に維持される潜在的な環境状態であり、at はエージェントのアクション(ツールの呼び出し)であり、ot+1 はエージェントに返される観測値です。従来のワールドモデルがデータから学習するのとは異なり、LES(Learning Environment Simulators)は、ドメイン固有の運用ロジックに関する事前学習済みの知識を活用します。
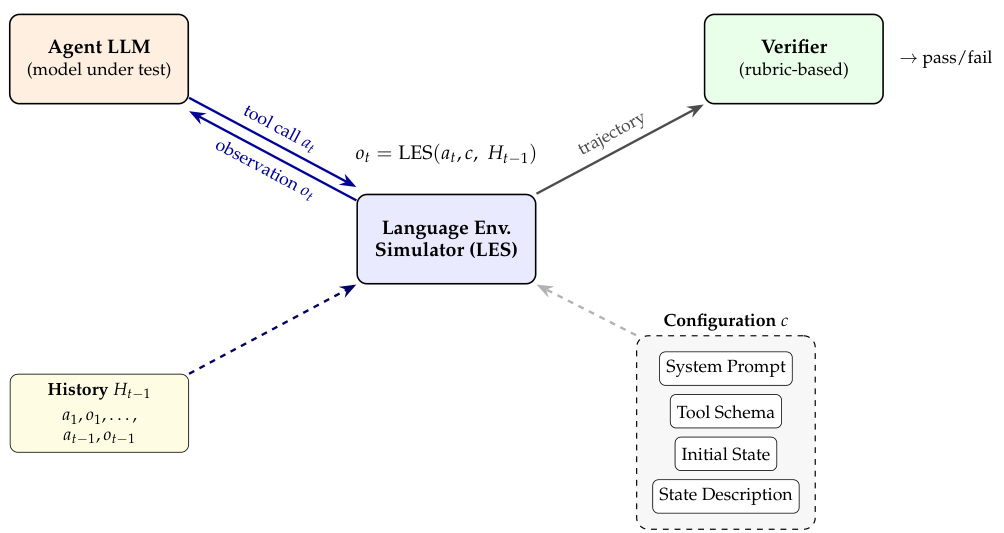
環境設定
システムプロンプト
この環境は、システムの動作ルール、シミュレーションロジック、エラー処理プロトコル、および出力形式に関する制約を定義します。例えば、ホテルの収益管理環境では、価格設定ルール、稼働率の計算、および指標間の関係が規定されます。
ツールスキーマ
エージェントのアクション空間を、型付きパラメータとサンプル出力を持つ呼び出し可能な関数群として定義します。各環境には、2~10個(中央値は5個)のツールが含まれており、これは現実的な運用インターフェースを反映しています。
初期状態
環境の初期状態を指定する構造化されたJSONオブジェクト。例えば、部屋の在庫、患者の待ち行列、またはネットワークの構成などが含まれます。
状態の説明
各ステートフィールドに対して、意味的な注釈を追加し、LLMが因果関係の一貫性を維持するように誘導します (例: 「予約ごとに残存在庫が減少する」)。
LLM(大規模言語モデル)がシミュレーターとして機能する理由。
LLM(大規模言語モデル)は、効果的な環境シミュレータである理由は以下のとおりです:(1) Format priors—APIドキュメントを用いた事前学習は、適切にフォーマットされたツール応答のための強力な事前知識を提供します。(2) Domain knowledge—LLMは、数百の職業における運用ロジックをエンコードしています。(3) Constraint enforcement—システムプロンプトによって、因果的一貫性を維持するための状態遷移ルールを課すことができます。
なぜこのアプローチは強力なのか?
AIエージェントのための従来のベンチマークでは、実際のソフトウェア環境を構築する必要があります。例えば、実際の病院管理システム、実際の工場スケジューリングツール、実際の通関処理APIなどです。そのため、適切なベンチマークが存在するドメインはほんのわずか(ウェブブラウジング、コーディングなど)です。 LESアプローチはこれとは逆のアプローチを取ります。環境を構築する代わりに、それらを自然言語で記述します。 LLMは、数百の業界のドキュメントで事前学習されているため、すでに「知っている」のです。例えば、救急部門システムがトリアージの問い合わせにどのように応答すべきか、またはロジスティクスAPIがルート最適化をどのように処理すべきか、といったことです。これにより、100の異なる専門分野のエージェントをベンチマークすることが可能になります。これは、従来のやり方では数百万ドルの費用がかかることです。