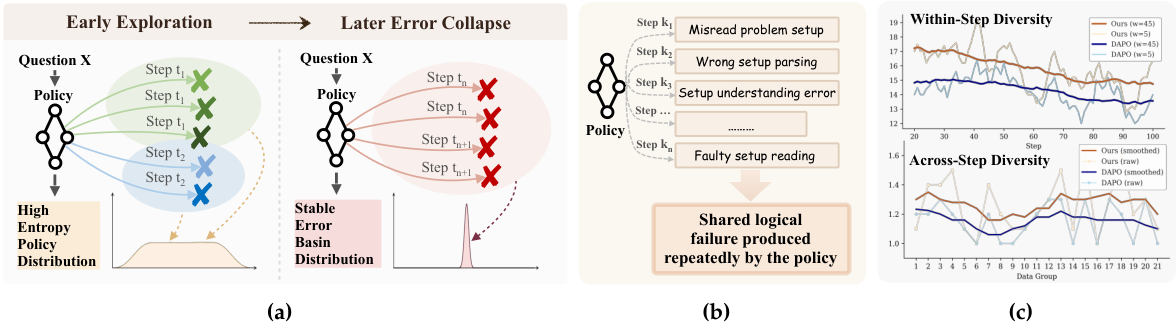
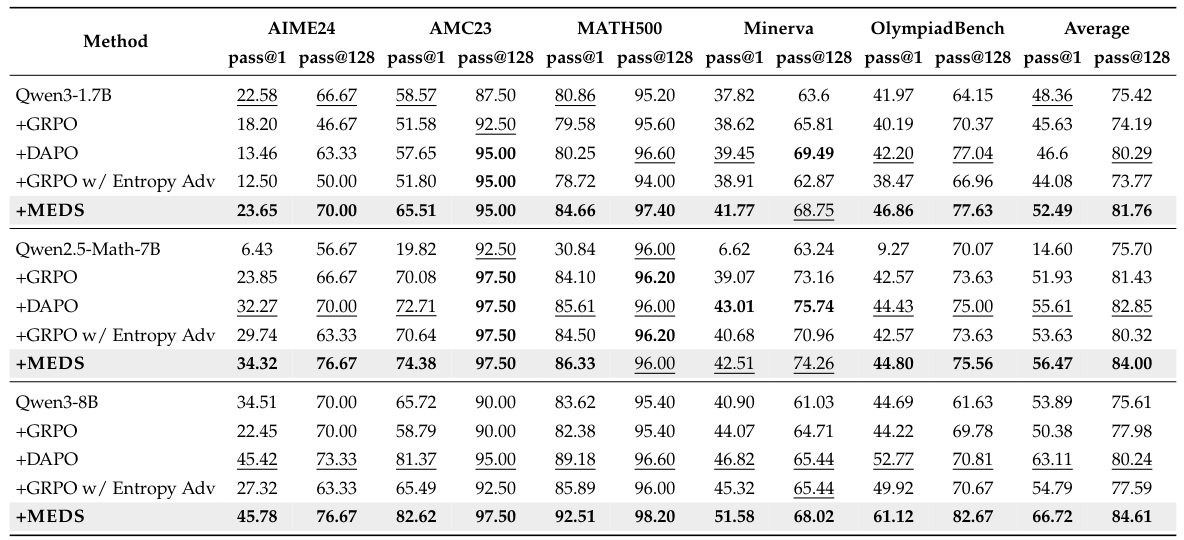
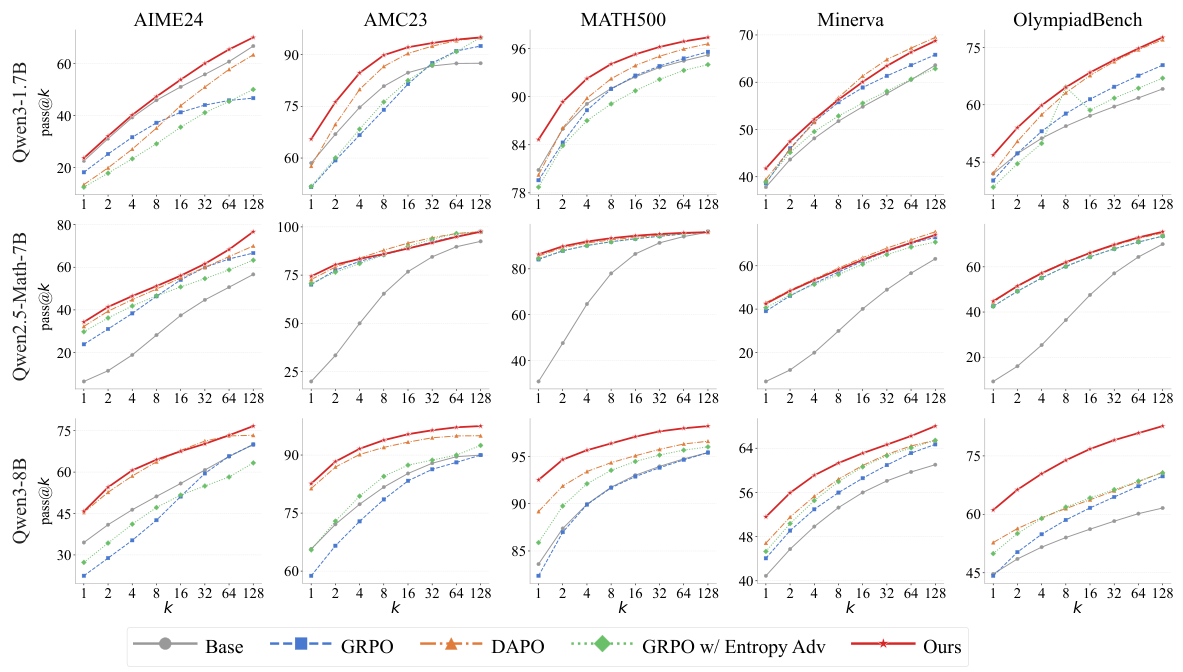
方法
MEDSフレームワークは、標準的な強化学習に、頻繁に発生するエラーパターンをターゲットとする、メモリベースのペナルティを追加します。入力 \(x \sim \mathcal{D}\) が与えられたとき、LLMポリシー \(\pi_\theta\) は、応答 \(y \sim \pi_\theta(y|x)\) を生成します。標準的なRLの目的は、期待される報酬 \(\mathbb{E}[r(x,y)]\) を最大化することです。MEDSは、この報酬関数を修正し、形状化された報酬を導入します。その式は \(r_s(x,y) = r(x,y) - \text{penalty}(c_i)\) であり、\(c_i\) は、応答の行動パターンに基づいたクラスタ割り当てです。
なぜモデル自身の内部信号を利用するのか?
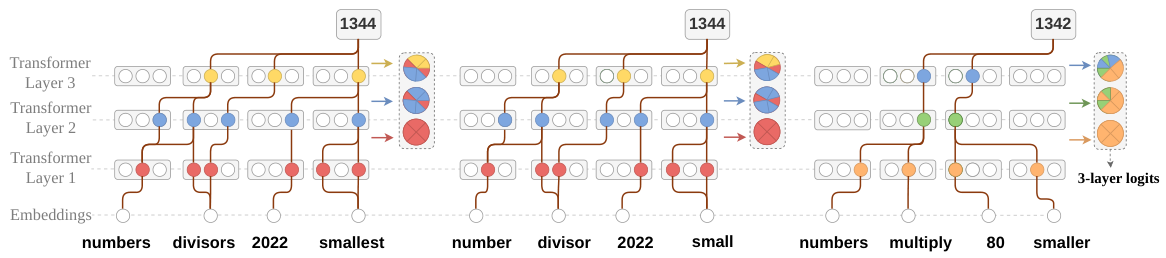
LLMがテキストを生成する際、単に単語を生成するだけでなく、各ステップで考えられるすべての次のトークンに対する確率分布を内部的に計算しています。これらの内部信号(logits )は、モデルの「思考プロセス」のようなものです。MEDSは、これらの信号を、各応答の推論戦略の指紋として利用します。数学の問題を解く2人の学生を考えてみましょう。彼らの書き出した答えが表面上異なって見える場合でも、もし彼らが同じ概念的な誤りを犯しているのであれば、彼らの内部的な推論パターンは似ているはずです。MEDSは、まさにこれを捉えています。モデルがどのように考えているか(how )に基づいて応答をグループ化し、単にモデルが何を書いているか(what )というだけでなく、その思考プロセスを考慮しているのです。
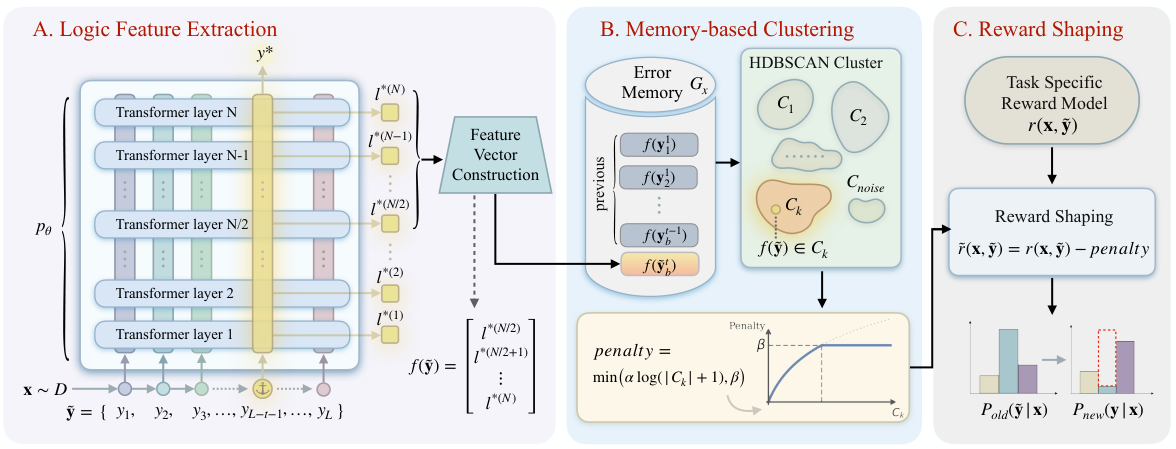
図2: MEDSフレームワークは、3つのモジュールで構成されています。(A) Logic Feature Extractionは、中間モデル表現から推論特徴を抽出します。(B) Memory-based Clusteringは、HDBSCANを使用して、メモリバッファから類似したエラーパターンをグループ化します。(C) Reward Shapingは、クラスタサイズに基づいたペナルティを適用し、反復的なエラーを抑制します。
反復発生するエラーに対するペナルティを科すことの理論的な利点
標準的な報酬関数 \(r(x,y)\) を用いると、更新されたポリシー \(q_1\) は、収益を最大化するパターンに収束します。一方、誤差クラスタへのペナルティ \(r(x,y) - \lambda c(y)\) を導入することで、修正されたポリシー \(q_2\) は、確率質量を大きな誤差クラスタから分散させるように、数学的に証明されて促進されます。
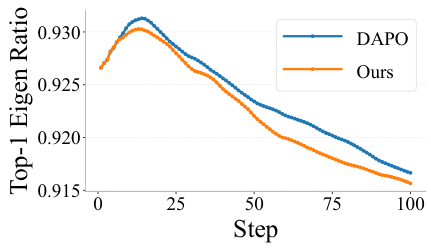
主要な理論的結果(定理2)は、形状化された報酬の下で、更新されたポリシー\(q_2\)が、期待される性能を維持しながら、より高いエントロピー\(H(q_2) \geq H(q_1)\)を達成することを示しています。これは、MEDSが品質を犠牲にすることなく、探索の多様性を確実に向上させることを意味します。
定理 2 (非公式): \(q_1\) と \(q_2\) を、それぞれ元の報酬関数 \(r(x,y)\) と、形状化された報酬関数 \(r(x,y) - \lambda c(y)\) の下で更新されたポリシーとします。このとき、\(H(q_2) \geq H(q_1)\) となり、これは形状化された報酬が、証明に基づき、出力の多様性を確実に増加させることを意味します。
この定理は、実際にどのような意味を持つのでしょうか?
定理2は、MEDSが意図したとおりに機能することを数学的に保証するものです。平たく言うと:最も一般的なエラーパターンに対してペナルティを科すことで、モデルは確実に、より多様な戦略を試すように強制されます
ロジック特徴抽出
指標関数 \(c(y)\) を実装するために、MEDS はモデル自身の内部表現を直接活用します。ポリシーによって生成される各応答 \(y\) に対して、この方法は特定の内部層から logit ベクトル を収集します。これらのベクトルは、例えばシーケンス内の位置に関する平均プーリングによって、固定次元の特徴ベクトルに統合されます。この特徴ベクトルは、応答の推論ロジックを捉えます。このアプローチは、計算効率が高いという利点があります。なぜなら、これらの表現は標準的な順伝播計算中にすでに計算されており、追加の推論は不要だからです。
ロジットベクトルとは?
ロジット とは、言語モデルが次のトークンに対する確率を計算する前に算出する、生のスコアのことです。例えば、モデルが次にどの単語が来るかを判断する場合、"the" に対して 5.2 のスコア、"and" に対して 3.1 のスコア、"banana" に対して -1.7 のスコアを割り当てる可能性があります。これらのスコア(ロジット)は、モデルの内部的な嗜好性を反映しています。MEDS は、最終的な出力層ではなく、中間層からこれらの情報を収集することで、単なる表面的な単語の選択だけでなく、基盤となる推論ロジック を捉えようとしています。
クラスタベースの報酬整形
構築された応答表現に基づいて、MEDSはHDBSCAN (ノイズを含むアプリケーションの階層的密度ベース空間クラスタリング)を使用してクラスタの割り当てを計算します。メモリバッファは、過去の実行からの特徴ベクトルを格納します。各新しいバッチについて、この方法は以下の手順を実行します。
現在のバッチ内のすべての応答に対して、ロジット特徴量を抽出します。
現在の機能と、メモリバッファに保存されている機能を組み合わせます。
HDBSCANを実行し、類似したエラーパターンのクラスタを特定します。
クラスタのサイズに比例したペナルティを計算します。クラスタが大きいほど(より頻繁なエラーパターンが見られるほど)、高いペナルティが与えられます。
最終的な報酬は次のようになります: \(r_s(x,y) = r(x,y) - \text{penalty}(c_i)\)、ここで、ペナルティ関数は割り当てられたクラスタのサイズとともに増加し、最も一般的な故障モードに対して直接的な圧力をかけます。
HDBSCANとは何か、そしてなぜそれを使うのか?
HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise) は、データポイントを、それらがどれだけ密集しているかに基づいてグループ化するクラスタリングアルゴリズムです。 K-meansとは異なり、HDBSCANは事前にクラスタの数を指定する必要がなく、クラスタを自動的に発見し、"ノイズ"(どのパターンにも適合しない応答)を処理できます。 これは、MEDSにとって理想的です。なぜなら、(1) エラーパターンが事前にいくつ存在するかを知ることができない、(2) 一部の応答は本当にユニークであり、クラスタに無理やり組み込むべきではない、(3) エラーパターンは特徴空間において不規則な形状を持つ可能性がある、という理由からです。