
cs.AI
RationalRewards: 推論報酬が視覚生成をトレーニング時・テスト時の両方で向上させる
HKUST
University of Waterloo
Alibaba
2026年4月13日公開
2026年4月13日公開
視覚生成のための多くの報酬モデルは、複雑な人間の好みを単一の不透明なスコアに圧縮し、その好みの背後にある理由を無視しています。RationalRewards は、この状況を改善するために、報酬モデルに、スコアリングする前に、明示的な、多次元的な評価を行うように学習させます。このモデルは、PARROT(Preference-Anchored Rationalization)という革新的なフレームワークを使用しており、このフレームワークでは、理由付けを、対比データから推論される潜在変数として扱います。これにより、報酬モデルは、単なる受動的な評価ツールから、アクティブな最適化ツールへと変貌し、以下の2つの相補的な戦略を可能にします。RL-based fine-tuning(強化学習ベースの微調整)は、パラメータ空間で行われ、Generate-Critique-Refine loops(生成-評価-改善ループ)は、プロンプト空間で行われます。注目すべきは、テスト時のプロンプト調整アプローチが、いくつかのベンチマークにおいて、パラメータの更新なしに、RLによる微調整と同等またはそれ以上の性能を発揮することです。
多次元の構造化された評価手法が、不透明な数値スコアに取って代わり、テキストの忠実性、画像の忠実性、視覚品質、およびテキストのレンダリングに関する、説明可能な評価を提供します。
報酬モデルを、根拠(rationale)を潜在変数として扱い、ELBO(Evidence Lower Bound)を3つの解釈可能な段階に分解することで学習する、変分推論に基づくフレームワーク。
パラメータ空間のチューニング(トレーニング時間)をRL(強化学習)を用いて行い、また、Generate-Critique-Refineのループ(テスト時間)を用いてプロンプト空間のチューニングを行うことで、パラメータの更新なしに、計算資源と品質のトレードオフを実現します。
視覚生成技術がフォトリアリスティックで、指示に従った出力へと進化するにつれて、これらの出力を評価する報酬モデルが、さらなる進歩を阻む大きな制約となっています。しかし、ほとんどの報酬モデルは、単一の数値で構成されるブラックボックスであり、多次元の人間の判断を単一の数値に圧縮します。この不透明性が、2つの重要な問題を引き起こします。
まず、reward hacking(報酬ハッキング):モデルは、スカラー信号のバイアスを悪用して、真に品質が向上しなくてもスコアを高くしようと学習します。次に、スカラースコアは、実行可能なフィードバックを提供しません。これらは、生成モデルに対して何かが間違っていることを示すだけで、何が間違っているのか、どのように修正するのかを教えてくれません。RationalRewardsは、これらの問題を、スコアを算出する前に構造化された多次元の批判を生成することで解決します。これにより、報酬モデルは、評価者と最適化ツールの両方として機能することができます。
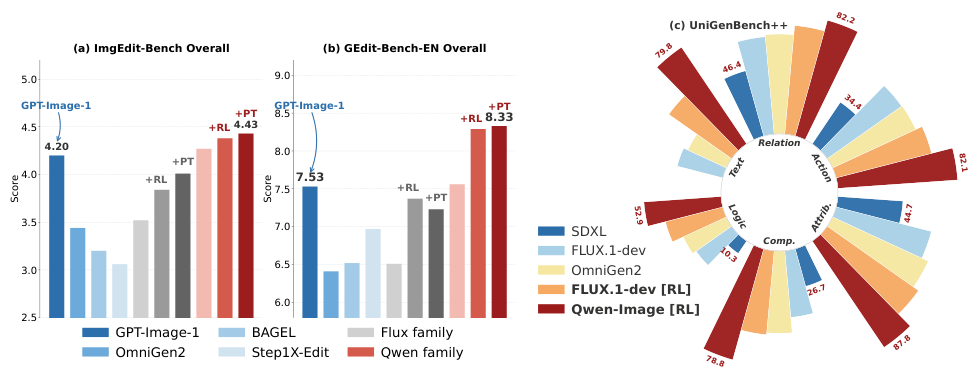
PARROTを用いてQwen3-VL-Instruct-8Bをベースに構築されたRationalRewardsは、オープンソースのリワードモデルの中で最先端の嗜好予測性能を達成しており、Gemini-2.5-Proと競合するレベルです。また、RLにおけるリワードとして、Qwen-ImageやFlux-Kontextのジェネレーターを継続的に改善し、GPT-Image-1に匹敵する性能を発揮します。テスト時のプロンプトチューニングのアプローチは、いくつかのベンチマークにおいて、計算コストの高いRLファインチューニングと同等またはそれ以上の性能を発揮します。しかも、パラメータの更新は一切行わずに。
PARROTは、スコアを算出する前に、明示的で多次元的な根拠を生成するための報酬モデルを訓練します。評価項目には、テキストの正確性, 物理的および視覚的な品質, 画像の正確性, および テキストのレンダリング品質が含まれます。真の根拠を大規模にアノテーションすることは非常にコストがかかるため、PARROTは、変分的な目的関数を用いて、ペアごとの嗜好データから推論される潜在変数として根拠を定式化します。その結果得られるELBOは、3つの項に分解され、それぞれがトレーニングの段階に対応しています。
ELBO(Evidence Lower BOund:証拠下限値)は、変分推論における数学的なツールです。これは、例えば、人間がなぜある画像と別の画像を好むのかを理解したいが、その思考プロセスを直接観察できない状況を考えてみてください。ELBOは、観察可能なデータ(どの画像が好まれたか)から、それらの隠れた理由(根拠)を学習する方法を提供します。
PARROTは、これを3つの直感的な要素に分解します。(1) その根拠は、実際に好みを説明しているのか? (2) 推論された根拠は、答えを知らない場合に生成されるものとどれくらい異なるのか? (3) 学生モデルは、それらの根拠を独自に生成することを学習できるのか?
潜在変数とは、存在すると信じているものの、直接観察できないものです。ここでは、「合理性」(ある画像がなぜ優れているかの理由)が潜在的です。人間は好みを示すことはありますが、その理由を完全に書き出すことはまれです。PARROTの洞察は、これらの観察されない合理性を潜在変数として扱い、詳細な理由付けを人間が記述する代わりに、嗜好データから学習することです。
現実世界の例: これは、星の評価(嗜好)のみを見て、あるレストランの優れたレビューを学習し、次にその評価につながる詳細なレビュー(合理性)を生成するモデルを訓練することに似ています。

Teacher VLMは、比較タプル(2つの画像+ユーザーからのリクエスト)と、正解の評価ラベルを受け取ります。このラベルは、教師の分析を正しい判断へと導く評価の基準点として機能し、条件なしの生成よりも高品質な確率分布を生成します。教師は、4つの品質次元にわたって構造化された評価を行い、スコアと根拠を提供します。
フェーズ1は、言語学的に妥当な根拠を生成しますが、妥当性だけでは有用性を保証するものではありません。フェーズ2では、予測可能性の充足性を強制します。具体的には、教師に対して、優先順位のラベルなしで根拠を再度質問し、元の優先順位を正しく予測する必要があります。この整合性チェックを通過した根拠のみが保持され、誤った情報や情報量が不十分な根拠が排除されます。
より小型のStudent VLM(80億パラメータ)は、フィルタリングされた説明文を用いて教師あり微調整を行い、好みのラベルなしで批判文を生成します。これにより、事後分布と事前分布のKLダイバージェンスが最小化され、Studentモデルは推論時に画像のみから評価理由を生成できるようになります。Studentモデルは、ペアごとのデータとポイントごとのデータを組み合わせて学習されます。
スカラー報酬モデルは、評価を単一の数値に圧縮しますが、この数値はバイアスを利用することで意図的に操作される可能性があります。一方、多次元で構造化された根拠(rationales)は、内部整合性のメカニズムを提供します。つまり、根拠はスコアと一致しなければならず、スコアはすべての次元で一貫していなければなりません。もしモデルが特定の次元を意図的に高くしようとしても、その根拠は、なぜそうなるのかを説明する必要があり、これにより不正行為を検出し、ペナルティを科すことが可能になります。このような構造的な透明性が、推論報酬の堅牢性をもたらします。
リワードハッキングとは、AIモデルが実際に品質を向上させずに、報酬スコアを最大化するための抜け道を見つける現象を指します。例えば、スカラー報酬モデルが彩度が高い画像に高いスコアを与える場合、生成モデルはすべての画像を過剰に彩度させることを学習し、視覚的な品質を低下させながらスコアを高く保つ可能性があります。
RationalRewardsは、多次元のスコアリングによって、この問題を防止します。なぜなら、テキストの忠実性が高いにもかかわらず、視覚的な品質が低い場合、その乖離は明らかであり、ペナルティの対象となるからです。

RationalRewardsは、単なる評価ツールではありません。これは、2つの補完的な領域において、アクティブな最適化ツールとして機能します。 この二重の構成は、テスト時の計算リソースのスケーリングと関連しており、プロンプト空間の最適化は、パラメータ空間でのトレーニングとは独立した軸を提供し、パラメータが固定されたジェネレーターに対して、破滅的な忘却のリスクなしに、生成品質を向上させることができます。
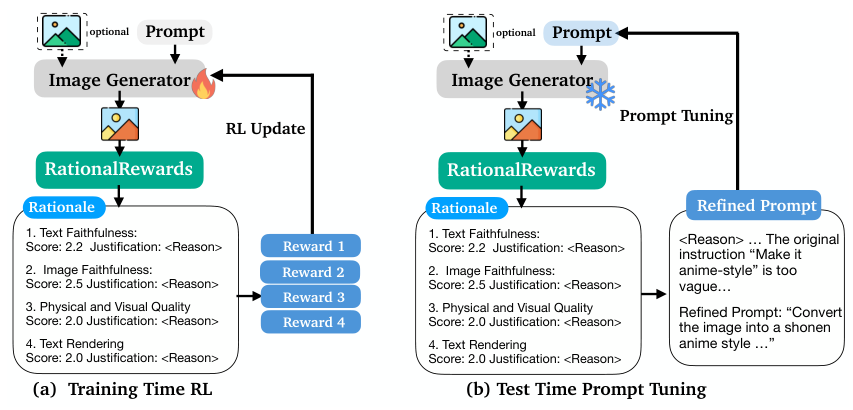
パラメータ空間最適化(RL)は、モデルの内部パラメータを変更します—まるで料理人のスキルを再訓練するようなものです。プロンプト空間最適化(GCR)は、モデルに与える指示書き換えます—まるで同じ料理人に、より良いレシピを与えるようなものです。
これらは直交であり、異なる次元で作用し、組み合わせて使用できます。重要な発見は、プロンプトの改善だけでもある程度の効果があり、場合によってはRLと同等またはそれ以上の性能を発揮することです。これは、現在の生成モデルが、デフォルトのプロンプトが示唆するよりも高い能力を持っていることを示唆しています。
ビジネスへの示唆:企業は、高価な再訓練なしに、推論時に画像の生成品質を向上させることができます。これは、既存のパイプラインに、批判と改善のステップを追加するだけで実現可能です。
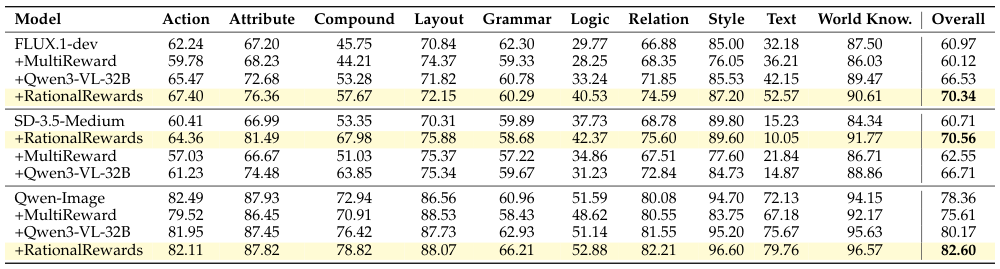
多次元のスコアは、強化学習において、意味的に分解された報酬信号を提供します。各品質次元(テキストの忠実性、画像の忠実性、視覚品質、テキストのレンダリング)は、特定の勾配情報を提供し、単一の不透明なスカラーを追いかけるのではなく、より詳細な最適化を可能にします。この密度の高いフィードバックは、生成モデルが何を改善すべきか、そしてなぜ改善すべきかを理解するのに役立ちます。
自然言語による説明は、生成された画像における具体的な欠点を特定します。例えば、「指示には傘を使用しないと書かれているが、画像には傘が含まれている」といったものです。これらの批判は、生成-批判-改善 (Generate-Critique-Refine, GCR) ループにおいて、特定のプロンプトの修正に翻訳されます。この純粋にテスト時に行われる介入は、パラメータの更新を必要とせず、どの固定された生成モデルにも適用でき、計算資源を品質と交換するものです。
なぜ、高性能な汎用的なVLM(例えば、Qwen3-VL-32B)を評価者として使用しないのでしょうか? 8Bモデルの方が実用的な利点があることに加えて、根本的な理由があります。それは、嗜好データを用いた構造化された学習が、汎用的なVLMが持たないキャリブレーションされた判断基準を学習させるからです。汎用モデルは批判を述べることができますが、重要度の調整ができません。そのため、軽微な問題に対して過剰なペナルティを与えたり、重大な欠陥を軽視したりする傾向があります。PARROTの嗜好性に基づく学習は、人間の実際の嗜好に基づいて判断を行うことで、この問題を解決します。
Generate-Critique-Refine (GCR) ループは、画像生成において テスト時の計算リソースのスケーリング を提供します。初期生成後、RationalRewards が出力に対して分析を行い、具体的な欠点を詳細な根拠とともに特定します。これらの分析結果はプロンプトの修正に変換され、ジェネレーターが再生成を行います。このテスト時のみに適用される手法は、パラメータの更新を必要とせず、任意の固定されたジェネレーター に適用可能です。これにより、現在のジェネレーターには潜在的な能力が内在しており、最適でないプロンプトではその能力が引き出されていないことが示されます。

ジェネレーターは、しばしば高品質な出力を行うための潜在能力を持っていますが、最適化されていないプロンプトによってその能力が十分に引き出されていないことがあります。RationalRewardsは、重みの変更なしに、具体的なフィードバックを通じてこの潜在能力を解放します。スカラー報酬は、何が問題なのかを特定することはできず、単に「何か」がうまくいかなかったという情報しか提供できません。構造化された推論は、具体的な問題点を特定し、具体的なプロンプトの修正方法を提案します。これにより、テスト時の計算リソースの効率的な利用が可能になります。
RationalRewards は、画像編集タスクとテキストから画像を生成するタスクの両方で評価されます。学習データには、EditReward (画像編集) からの 30,000 件のクエリ-好みのペアと、ImageRewardDB (テキストから画像) からの 50,000 件のペアが含まれます。Teacher は Qwen3-VL-32B-Instruct であり、Student のバックボーンは Qwen3-VL-8B-Instruct です。
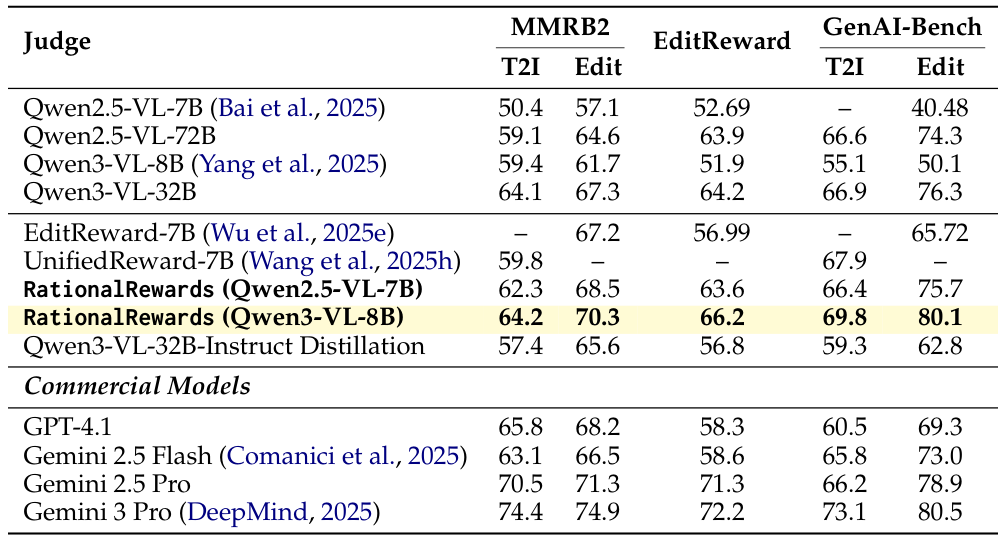
8BパラメータのRationalRewardsは、全てのオープンソースのスケール報酬モデルを大幅に上回ります。 これは、MMRB2、EditReward-Bench、GenAI-Benchの3つのベンチマークすべてにおいて、ラベルノイズに対処するための複雑な損失設計を必要とせずに、その性能を発揮します。 また、はるかに大規模なプロプライエタリモデルであるGemini-2.5-Proにも匹敵する性能を持っています。 アブレーション実験の結果、PARROTの変分フレームワークは、同じ32Bの教師モデルからの直接的なSFT蒸留よりも優れた性能を発揮し、モデルの規模だけでなく、構造化されたトレーニングパイプラインが性能向上に大きく貢献していることを示しています。
RL with RationalRewards は、画像編集とテキストから画像への生成の両方において、一貫した改善をもたらします。注目すべき発見として、推論時間におけるプロンプト調整が、計算コストの高い RL と同等またはそれ以上の効果を発揮することが挙げられます。ImgEdit-Bench において、プロンプト調整は、RL で調整された Flux モデルの性能を 3.84 から 4.01 に向上させました。これは、プロンプト空間の最適化が、パラメータ空間での学習とは異なる、補完的なアプローチであることを支持するものです。
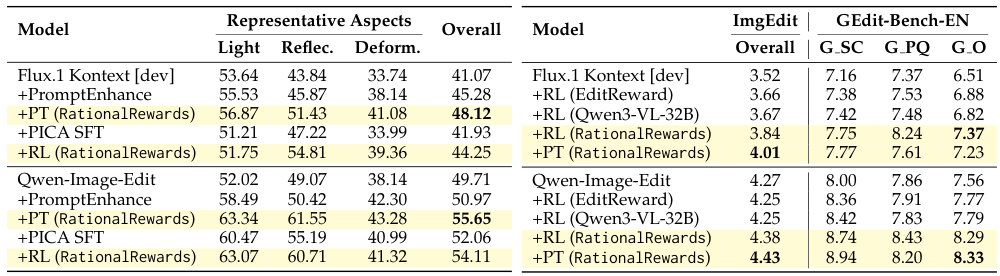
この論文の中で最も注目すべき結果の一つは、テスト時のプロンプトチューニングが、高価な強化学習による訓練と同等またはそれ以上の性能を示すことが多いということです。これは直感に反するかもしれません。モデルの重みを変更する(強化学習)方が、単にプロンプトを書き換えるよりも強力であると予想されるでしょう。
その理由:LoRAを用いた強化学習は、更新能力に限界があり、評価データの全範囲をカバーできない可能性があります。プロンプトチューニングは、個々のインスタンスに対して最適化を行うため、破滅的な忘却のリスクを伴いません。さらに、これは現在の生成モデルがすでに優れた出力を生成する能力を持っていることを示唆しており、単に、より良い指示が必要なのです。
実践的な示唆:高価な強化学習の再訓練に投資する前に、構造化された批判的なフィードバックを用いてプロンプトを改善してみてください。同様の結果を、はるかに低いコストで得られる可能性があります。


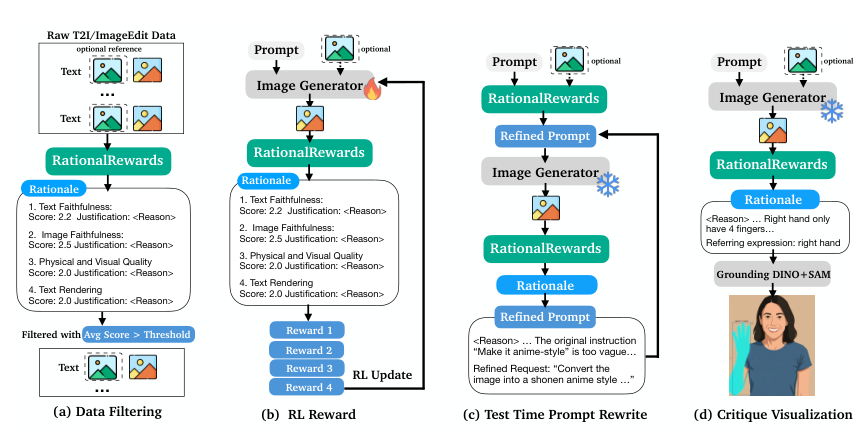
多次元のスコアと説明可能な根拠を用いた、データキュレーションのための自動品質管理システム。品質の低いトレーニングデータは、透明性をもって特定され、フィルタリングされます。
密で、意味的に分解された報酬信号が、詳細な強化学習の最適化を促進します。各品質次元は、単一の不透明なスカラーではなく、ターゲットを絞った勾配情報を提供します。
GCRループは、推論時の計算コストを生成品質の向上とトレードオフにします。パラメータの更新や、破滅的な忘却のリスクなしに、任意の固定されたジェネレーターに適用可能です。
Grounding DINO+SAMとの連携により、生成された画像内で特定された欠陥が特定され、画像内の特定領域に根ざした具体的な根拠となる視覚的な証拠が提供されます。
RationalRewardsは、不透明なスカラー評価を、構造化された、多次元的な思考プロセスに基づく批判に置き換えます。PARROTフレームワークは、合理性を、容易に入手可能なペアワイズの好みデータから抽出できる潜在変数として扱うことで、この問題を解決します。
8Bパラメータのモデルは、オープンソースのリワードモデルの中で、最先端の好みの予測精度を達成しており、はるかに大規模なプロプライエタリモデルにも匹敵します。多次元のリワードは、スカラーモデルでは提供できない内部整合性メカニズムを通じて、リワードハッキングへの耐性を持ちます。
おそらく最も注目すべき点は、Generate-Critique-Refine ループ—これはパラメータの更新を必要としない、純粋にテスト時に行われる手法—が、いくつかのベンチマークにおいて、強化学習(RL)ベースのファインチューニングと同等またはそれ以上の性能を示していることです。この結果は、現在の生成モデルが潜在的な能力を秘めているものの、最適ではないプロンプトではその能力を引き出すことができず、構造化された推論がその潜在能力を解き放つ鍵となるという仮説を強く裏付けています。