ClawGUI: GUIエージェントの学習、評価、およびデプロイメントのための統合フレームワーク。
GUIエージェントは、原理的には、タップ、スワイプ、キー入力などを通じて、あらゆるデバイス上のあらゆるアプリケーションを操作することができます。しかし、実際には、進捗はモデリングの問題ではなく、フルスタックインフラストラクチャの不足によってボトルネックになっています。具体的には、クローズドな強化学習(RL)のトレーニングコードベース、静かに変化していく評価プロトコル、そして研究から実際のユーザーへの繋がりの欠如が問題です。 ClawGUI は、これらの3つの問題をすべて解決します。具体的には、エミュレーターや実機でのスケーラブルなオンラインRL、6つのベンチマークと11以上のモデルにおける再現可能な評価、そして12以上のチャットプラットフォームを通じた実機への展開を、単一のオープンソースパイプラインの中で実現します。
概要
GUIエージェントは、プログラム的なAPIではなく、視覚的なインターフェースを通じてアプリケーションを操作し、タップ、スワイプ、キー入力などを通じて、あらゆるソフトウェアとインタラクトします。これにより、CLIベースのエージェントでは対応できない、ニッチなアプリケーションにも対応できます。しかし、その進歩は、モデリング能力の限界よりも、一貫性のあるフルスタックインフラストラクチャの欠如によって阻まれています。オンライン強化学習のトレーニングは、環境の不安定性やクローズドパイプラインによって困難になり、評価プロトコルは研究間で静かに変化し、訓練されたエージェントが実際にユーザーの実際のデバイスに到達することは稀です。
ここでは、これらの3つの課題を1つのフレームワークで解決するオープンソースのフレームワークであるClawGUIをご紹介します。ClawGUI-RLは、検証済みのサポートを備えた、初のオープンソースのGUIエージェント強化学習インフラストラクチャであり、並列仮想環境と実際の物理デバイスの両方に対応しています。また、GiGPOをプロセス報酬モデルと統合し、詳細なステップレベルの監視を実現しています。ClawGUI-Evalは、6つのベンチマークと11以上のモデルに対して、完全に標準化された評価パイプラインを適用し、公式のベースラインに対する95.8%の再現性を達成しています。ClawGUI-Agentは、トレーニングされたエージェントを、12以上のチャットプラットフォームを通じてAndroid、HarmonyOS、およびiOSに提供し、ハイブリッドのCLI-GUI制御と、永続的なパーソナライズされたメモリを実現します。
このパイプライン内でエンドツーエンドで学習されたClawGUI-2Bは、MobileWorldのGUIのみを使用したタスクで17.1%の成功率を達成し、同規模のMAI-UI-2Bのベースラインを6.0ポイント上回っています。また、Qwen3-VL-32B (11.9%)やUI-Venus-72B (16.4%)といった、より大規模で未学習のモデルも上回っています。
一つのフレームワーク、そして3つの緊密に統合されたモジュール。
ClawGUI-RL
並列化されたDockerベースのAndroidエミュレータと実際の物理デバイスにまたがる、スケーラブルなオンライン強化学習(RL)トレーニング。GiGPOをプロセス報酬モデルと統合し、密度の高いステップごとの監督を実現することで、長期的な報酬の疎性を抑制します。
ClawGUI-Eval
厳格な3段階のパイプライン(推論 → 評価 → メトリック)を採用し、各モデルの評価におけるすべての選択肢を固定しています。6つのベンチマーク、11種類以上のモデルを使用し、公式に公開されているベースラインに対する再現率は95.8%です。
ClawGUI-Agent
Android、HarmonyOS、およびiOS向けの、本番環境での利用可能な展開を、12種類以上のチャットプラットフォームを通じて提供します。ハイブリッドなCLI+GUI制御と、個々のユーザーに合わせて時間とともに適応する、永続的なパーソナライズされたメモリシステムを備えています。
GUIエージェントがインフラストラクチャに固執する理由.
グラフィカルユーザーインターフェース(GUI)は、人間が現代のコンピューティングデバイスと対話するための普遍的な基盤です。画面の状態を認識し、タップ、スワイプ、タイピングといった低レベルな操作を実行できるエージェントは、原則として、専用のAPIやバックエンドアクセスを必要とせずに、あらゆるデバイス上のあらゆるアプリケーションを操作できます。この汎用性により、GUIエージェントは、エンドツーエンドのデジタル自動化に向けた最も活発に研究されている分野の一つとなっています。
しかし、高性能なGUIエージェントを構築するには、単なるモデリングの問題ではなく、フルスタックのエンジニアリングの問題です。有用なエージェントは、現実的な環境でトレーニングされ、比較可能な条件下で評価され、最終的には実際のユーザーが恩恵を受けられるように、実際のデバイスにデプロイされる必要があります。既存の研究では、これらの各側面において目覚ましい進歩が見られていますが、これらの要素を組み合わせて動作するパイプラインを構築しようとすると、その間のギャップが明らかになります。
我々は、このボトルネックを特徴づける3つの具体的な課題を特定しました。
トレーニングのエコシステムは閉鎖されています。
最近のシステムでは、仮想環境におけるオンライン強化学習(RL)から優れた結果が報告されていますが、その基盤となるインフラストラクチャが公開されることはほとんどありません。公開されているコードは、エミュレーターのサンドボックスに特化しており、エージェントが最終的に動作する必要がある物理デバイス上での学習は、オープンな文献ではほとんど研究されていません。技術的な課題は、RLアルゴリズム自体ではなく、環境管理にあります。エミュレーターは、長時間の実行中に正常な状態から逸脱し、実際のデバイスはシステムレベルの検証信号を公開できません。また、長期的なGUIタスクにおける報酬信号は、設計上、ほとんどの場合、非常に少ない値しか得られません。
評価が著しくずれている。
GUIベンチマークは一見単純に見えますが、発表された数値は、論文間でほとんどの場合、直接比較できません。プロンプトの形式、座標の正規化、画像解像度、およびサンプリング構成は、それぞれ報告される精度を数ポイント変化させ、これらの選択はしばしば記録されていません。ScreenSpot-Proにおける2%の改善は、真の進歩、有利なプロンプト、または単に異なる解像度を表している可能性があります。そして、今日、読者はそれを判断する方法がありません。
デプロイメントのサイクルが中断されています。
研究パイプラインで訓練されたエージェントがエンドユーザーに届くことはほとんどありません。最近の研究では、CLIベースのツールが構造化されたコマンドによる精密な制御を提供していますが、これは実際のアプリケーションのごく一部しかカバーしていません。訓練されたGUIポリシーを実際のハードウェアに接続し、ユーザーが日常的に使用するインターフェースを通じて公開し、時間の経過とともに持続的なパーソナライズを維持するシステムは、オープンなエコシステムでは依然としてほとんど存在しません。
これらの知見に基づき、私たちはClawGUIを提案します。これは、3つの課題を1つのまとまったシステムで解決するために設計された、オープンソースのフレームワークです。ClawGUIは、以下の3つの密接に統合されたモジュールで構成されています。ClawGUI-RLは、GiGPOとプロセス報酬モデルを使用した、エミュレーターと実機の両方でスケーラブルなオンライン強化学習を可能にします。ClawGUI-Evalは、6つのベンチマークと11以上のモデルに対する、厳格な3段階の標準化された評価を行います。そして、ClawGUI-Agentは、12以上のチャットプラットフォームで、ハイブリッドのCLI-GUI環境での展開を可能にし、永続的なパーソナライズされたメモリを提供します。
主な貢献.
- 私たちは、GUIエージェント向けの単一のパイプラインとして、オンラインの強化学習(RL)トレーニング、標準化された評価、および実機へのデプロイメントを統合した、オープンソースの統合フレームワークであるClawGUIをリリースしました。
- 私たちは、ClawGUI-RLをリリースします。これは、大規模な並列仮想環境と実際の物理デバイスの両方をサポートする、検証済みのオープンソースGUIエージェントRLインフラストラクチャであり、GiGPOをプロセス報酬モデルと統合し、詳細なステップレベルの監視を可能にします。
- 私たちは、ClawGUI-Evalをリリースします。これには、推論コードと、6つのベンチマークおよび11以上のモデルに対する事前計算された予測データが含まれており、公式のベースラインに対する95.8%の再現率を達成し、信頼性の高い論文間の比較を可能にします。
- 当社は、ClawGUI-Agentをリリースしました。これは、訓練済みのエージェントを、パーソナライズされた永続的なメモリを備えた、12種類以上のチャットプラットフォームを通じて、実際のAndroid、HarmonyOS、およびiOSデバイスに接続する、実用的なデプロイメントシステムです。
- 弊社は、ClawGUI-2B をリリースします。これは、ClawGUI-RL 内でエンドツーエンドで学習されており、MobileWorld GUI-Only で 17.1% の精度を達成し、同規模の MAI-UI-2B のベースラインを 6.0 ポイント上回っています。これにより、フレームワーク全体の有効性が検証されました。
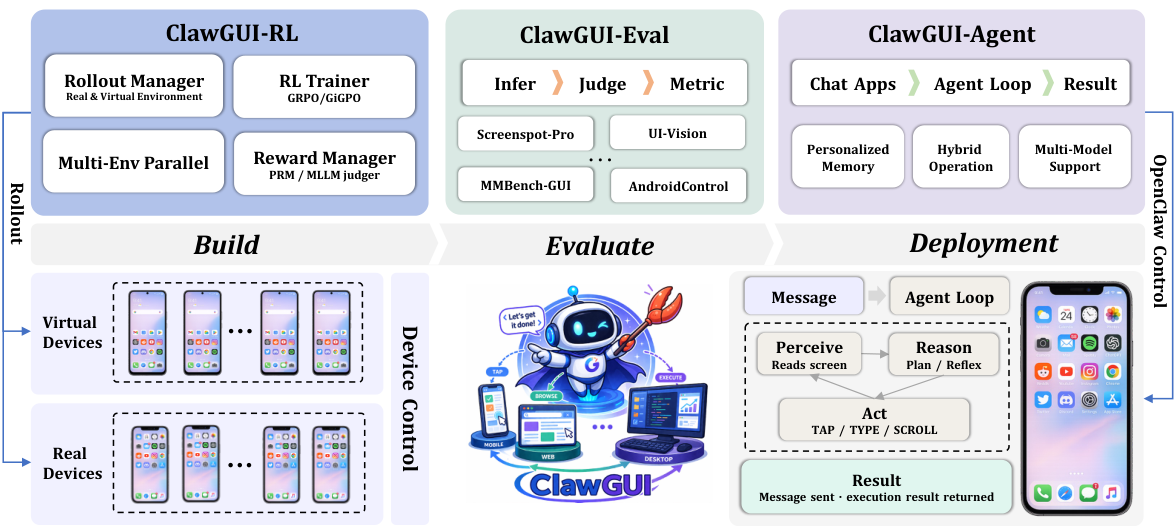
エミュレータおよび実機上での、スケーラブルなオンライン強化学習。
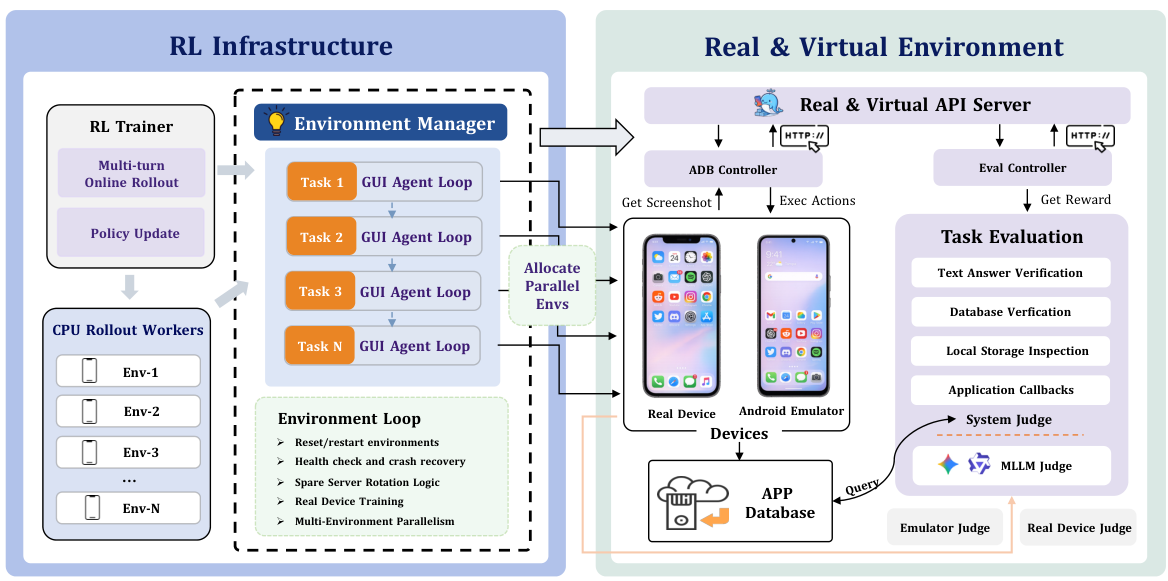
環境管理者
GUIタスクに対するオンライン強化学習(RL)のトレーニングにおいて、安定性と拡張性を備えた環境管理が真に不可欠です。Environment Managerは、タスクのリセット、仮想サンドボックス上でのシステムレベルのタスク評価、ヘルスチェック、スペアサーバーへの切り替え(正常に動作しないコンテナは、実行を停止することなく切り替えられます)、定期的なリセット、および、MLLMを評価者としてのみ利用できるリアルデバイスでのトレーニングを処理します。このレイヤーこそが、トレーニングの実行時間を数分から数時間に延長することを可能にしています。
二段階報酬設計
報酬は2つのレイヤーを組み合わせます。まず、二値結果報酬(エピソードの終わりに成功すれば1、失敗すれば0)は、ロバストですが、長期的なタスクでは非常に疎です。次に、密なステップごとの報酬を、プロセス報酬モデル(Process Reward Model, PRM)が各ステップで出力します。PRMは、前のスクリーンショット、現在のスクリーンショット、そして行動を入力として受け取り、そのステップが有益かどうかを評価します。これらを組み合わせることで、純粋な結果報酬では実現できない、最適化アルゴリズムに対するきめ細かい貢献度評価が可能になります。
RL トレーナー:GRPO および GiGPO
ClawGUI-RLは、verlとverl-agentを基盤としており、Reinforce++、PPO、GRPO、GSPO、およびGiGPOを標準でサポートしています。GRPOは、エピソードごとに単一の利得スコアを割り当てますが、これは、成功が数個の重要なステップにかかっている長い軌跡にとっては粗すぎる場合があります。GiGPOは、さらに細かいステップレベルのグループ化を追加し、各ステップの利得を、アンカー状態のクラスタリングによって推定します。つまり、同じ中間状態に到達するステップは、サブグループを共有し、相対的な利得を得ます。これにより、ポリシーは各ステップに対して詳細な利得情報を提供しつつ、エピソードレベルの全体的なシグナルを維持します。
再現可能なGUI評価。モデルごとに固定。
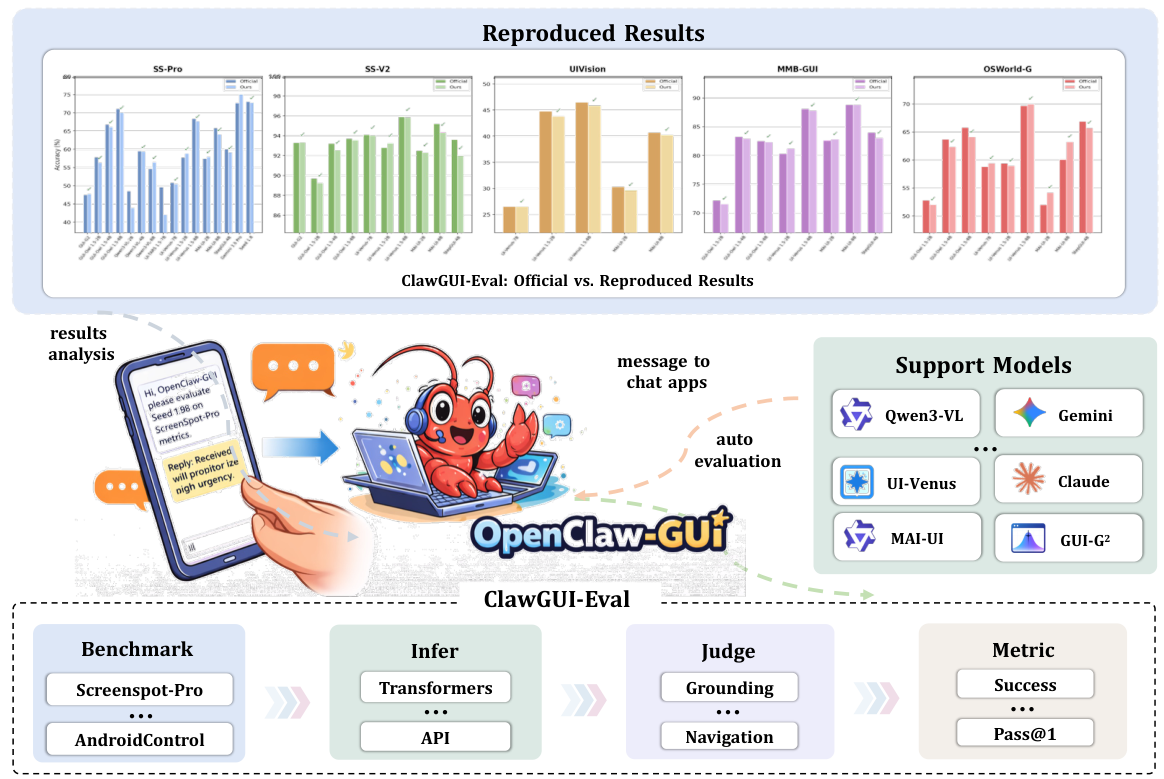
推測する。
指定されたベンチマークとターゲットモデルに基づいて、生の予測結果を生成します。ローカルGPUでの推論(Transformers)と、リモートAPIによる推論の両方をサポートしています。プロンプトのフォーマット、座標の正規化、画像解像度、およびサンプリング温度は、評価時に選択するのではなく、モデルごとに固定されています。
裁判官
生成されたモデルの出力は、ベンチマーク固有の評価基準に基づいて評価されます。具体的には、標準的なオブジェクト検出には「点-ボックス」評価基準、複雑なレイアウトには「ポリゴン/領域」評価基準、ナビゲーションの目標達成にはMLLM(大規模言語モデル)ベースの評価基準が用いられます。更新された解析器を用いて、以前の予測結果を再評価することは無料で、再評価を行う際に推論処理を再度実行する必要はありません。
メトリック
各サンプルに対するラベルは、プラットフォーム、UI要素のタイプ、およびタスクカテゴリごとに分類された、精度/Pass@1スコアに集約されます。すべての暫定的なデータ(予測、判断、スコアなど)は標準化され、これにより、誰でも同じ予測を独立して再評価することができます。
ベンチマークとモデルの網羅性
ClawGUI-Evalは、GUIの理解とナビゲーションに関する6つのベンチマークを網羅しており、クローズドソースとオープンソースの両方のファミリーに属する11種類以上のモデルをサポートしています。全体的な再現率は、公開されているベースラインと比較して95.8%(公式データのある48個のセル中、46個で再現)。
研究パイプラインから、実際のユーザーのスマートフォンまで。
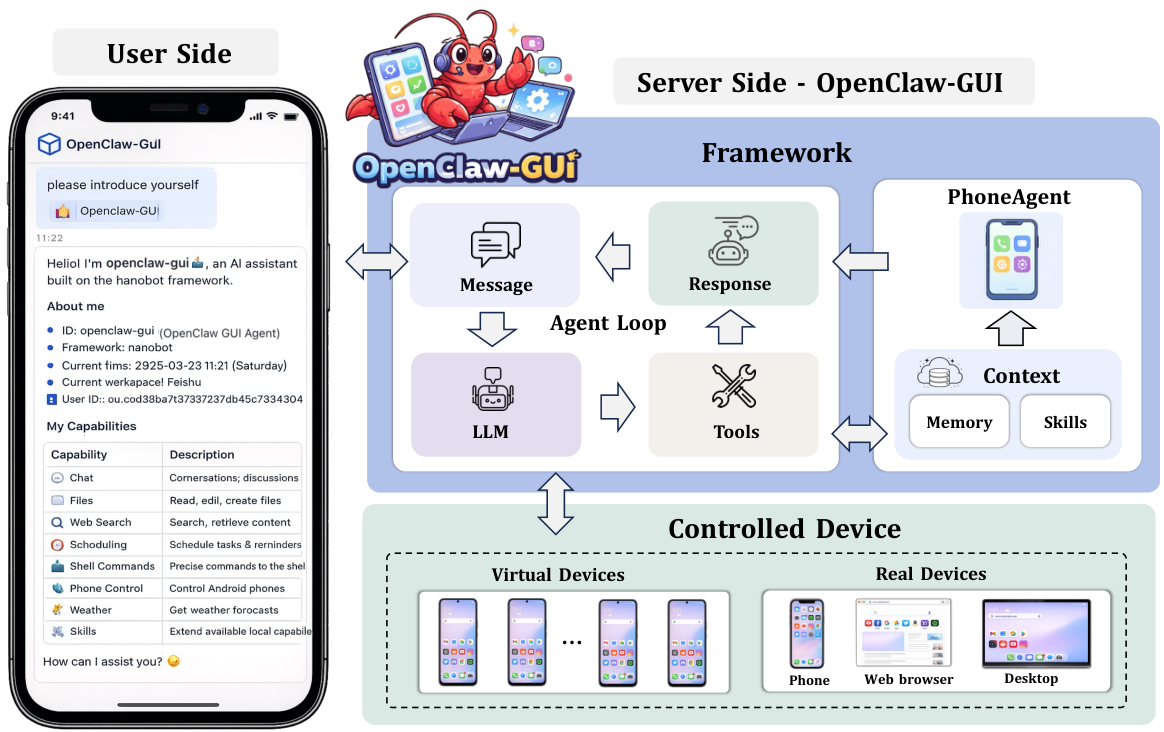
ハイブリッド CLI + GUI 制御
CLI(コマンドラインインターフェース)だけ、またはGUI(グラフィカルユーザーインターフェース)だけでは不十分です。CLIは正確ですが、プログラムによるインターフェースを持つアプリケーションにしか対応できません。GUIは幅広い対応が可能ですが、操作の手間が増えます。ClawGUI-Agentは、インターフェースが利用可能な場合はCLIの効率性を活用し、そうでない場合は、ピクセルレベルでのGUI操作にフォールバックすることで、正確性と広範な対応力を両立しています。
パーソナライズされた記憶
パーシステントなパーソナライズされたメモリシステムは、インタラクションから構造化された事実を自動的に抽出し、連絡先の名前や関係、頻繁に使用されるアプリケーション、繰り返されるプロセス、好みなどを特定し、これらの情報を将来のタスクにおいてエージェントのコンテキストにフィードバックします。これにより、エージェントは時間の経過とともに、特定のユーザーに対するサービスの提供能力を向上させることができます。
リモート制御とローカル制御
同じエージェントランタイムが、ローカルエミュレーター、ユーザーの机にある物理的なスマートフォン、またはリモートのデバイスファームを駆動します。リモートコントロールモードでは、エージェントは12以上のチャットプラットフォーム(Feishu、DingTalk、Telegram、Discord、Slack、QQなど)を通じてアクセス可能であり、ユーザーは毎日利用しているアプリからタスクを実行できます。
ClawGUI-Evalをデプロイ可能なスキルとして活用する.
ClawGUI-Evalは、エージェントに対して、主要なツールスキルとして提供されます。単一の自然言語コマンドによって、完全なベンチマーク評価パイプラインが起動されます。これにより、評価システム自体がエンドユーザーが利用できるものとなり、研究から実際の利用までのサイクルを完結させることができます。
パイプライン全体が正常に機能することを確認する。
ClawGUI-2Bは、ClawGUI-RL内でエンドツーエンドで学習されます。学習は、MAI-UI-2Bから開始し、8×A6000 (48GB)のGPUを搭載した64個の並列Dockerベースの仮想環境を使用し、GiGPO(ロールアウトグループサイズ: 8)を用いて行われます。評価は、MobileWorld GUI-Only(ビジョンのみで現実世界のモバイルインタラクションを必要とする117のタスク)および、完全なClawGUI-Evalベンチマークを用いて行われます。
主な結果
あらゆるステップが重要です:高密度報酬は、より優れたGUIポリシーの実現を可能にします。
GRPOは、各エピソードに対して単一の利得スコアを割り当てますが、これは長期的なGUIタスクには粗すぎるため、軌道の中盤で成功を収めたとしても、初期の誤ったクリックが隠蔽されてしまう可能性があります。GiGPOは、アンカー状態に基づいてステップをグループ化します。同じ中間状態に到達するステップは、サブグループにまとめられ、各グループ内で割引されたリターン正規化によって、各ステップの利得が推定されます。

GiGPOによる詳細なステップごとの監視は、エピソードレベルのGRPOと比較して17.9%の相対的な改善をもたらし、これは、GUIエージェントの強化学習において、詳細な報酬割り当てが重要な要素であり、オプションの付加機能ではないことを裏付けています。
ベンチマークのベンチマーク:公開されているGUIの数値は信頼できるのか?
再現性は、意味のある進歩のための前提条件ですが、GUIの評価は、残念ながら再現が非常に困難です。プロンプトの順番、座標の正規化、画像の解像度、およびサンプリングの設定は、報告される精度を数ポイントずつ変動させます。そして、これらの選択肢は、しばしば記録されていません。
ClawGUI-Evalは、各モデルにおける評価の選択肢を個別に記録し、6つのベンチマークと11以上のモデルに対して、厳密な3段階の「推論 → 評価 → 指標」のパイプラインを採用しています。全体的な再現率は95.8%(公式のベースラインと比較した48個のセルのうち46個)。オープンソースモデルの再現率は95.7%です。クローズドソースモデルは、APIレベルのサンプリングのばらつきが評価者の制御範囲外であるため、わずかに再現が難しい傾向があります。
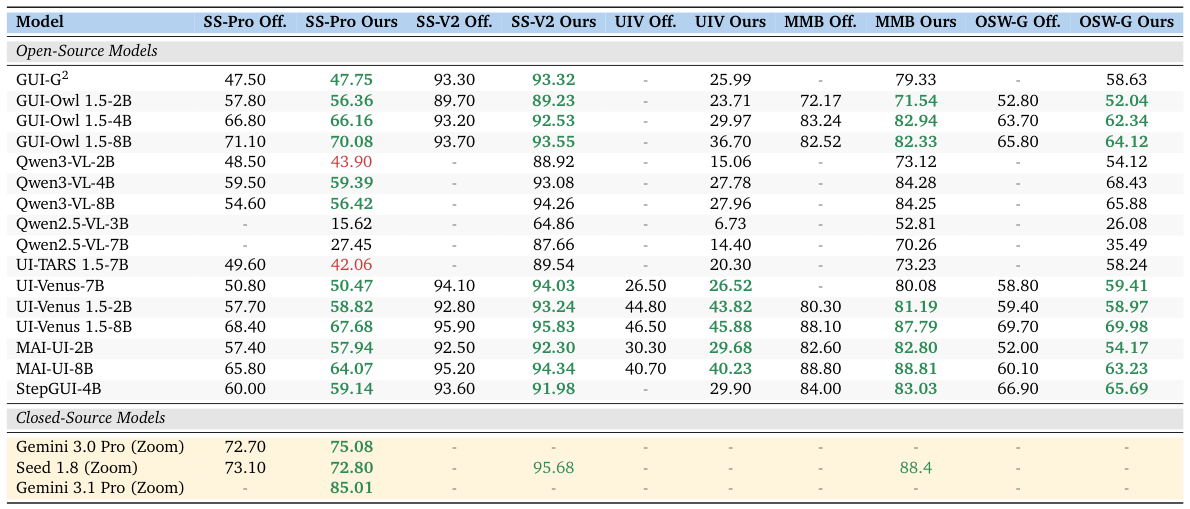
論文を、それぞれの論文で報告されている数値に基づいて比較しないでください。標準化された評価方法と固定された評価項目を用いることで、公開されているGUIのスコアが、再現可能なスコアとわずかながら一貫して異なることが示されています。異なる論文間の比較には、個々のランキングへの信頼ではなく、共通のインフラストラクチャが必要です。
これは、GUIエージェントの来年について何を語っているのか。
GUIとCLIを統合した、エージェント制御システムへの取り組み。
ここ1年間の最も重要な教訓は、Claude CodeやHermes Agentから、MiniMax M2.7の自己進化ループまで、エージェントの進歩は、トレーニング、評価、そして実際の運用環境が一体となって設計されたときに起こる、ということです。ClawGUIのハイブリッドCLI+GUI制御は、適切な基盤は単なるCLIだけではなく、単なるGUIだけではなく、両方を兼ね備えた単一のシステムであり、タスクに応じて適切なツールを選択できるものである、という明確な方針に基づいています。
オンライン強化学習 (RL) をエミュレーターの範囲を超えて拡張する.
現在のGUIエージェントの強化学習(RL)のトレーニングは、ほぼ完全にエミュレーターのサンドボックスに限定されており、これらは実際のアプリケーションの動作とは異なり、実際の利用で主流となっているアプリケーションをカバーできません。コード生成のような、認証を必要としないタスクの配布方法で、実際のインタラクションの流れを模倣し、実際のユーザー認証情報を使用せずに、プライバシーを保護する軌跡収集とオンデバイスでの強化学習を組み合わせることで、実際の展開が求める規模でのトレーニングが可能になります。
デバイス上で常に動作するシステムエージェントの開発に向けて。
デバイス上での推論が実用的なものになるにつれて、GUIエージェントの最終的な形は、オンデマンドで呼び出されるリモートサービスというよりも、ローカルで動作する、持続的なシステムレベルのインテリジェンスに近づいてきます。それは、ユーザーが見ているものを認識し、以前のコンテキストを記憶し、個々のアプリケーションとの統合なしに、さまざまなアプリケーション間で動作することができます。
GUI環境のためのワールドモデル.
今日のGUIエージェントは、反応的に動作します。つまり、スクリーンショットを観察し、アクションを予測し、フィードバックを待ちます。しかし、それらが欠けているのは、候補となるアクションに対して画面がどのように変化するかという内部モデルです。GUIの世界モデルがあれば、エージェントはアクションを実行する前に、いくつかの候補アクションをシミュレーションできます。これは、ロボティクスやゲームプレイに変革をもたらした、まさに同じ種類の一般化です。
オープンな技術スタックであり、コミュニティが発展させることができる基盤です。
私たちは、ClawGUIをご紹介します。これは、オンラインの強化学習(RL)トレーニング、標準化された評価、および実際のデバイスへの展開を、GUIエージェント開発のための単一の、一貫性のあるパイプラインに統合する、統一されたオープンソースのフレームワークです。ClawGUI-RLは、並列エミュレータと実際の物理デバイスの両方で検証された、最初のオープンソースのインフラストラクチャを提供します。ClawGUI-Evalは、コミュニティに共有可能な、再現性の高い評価環境を提供します。ClawGUI-Agentは、継続的なパーソナライズされたメモリを備えた、日常的なチャットアプリケーションを通じて、研究からエンドユーザーまでのフィードバックループを閉じます。
ClawGUI-2Bは、このパイプライン内でエンドツーエンドで学習されており、MobileWorld GUI-Onlyデータセットにおいて17.1%の精度を達成しました。これは、このフレームワークが単なる研究成果以上の価値を持つことを示しており、コミュニティがそれを基盤として構築できる、実用的な基盤となるものであることを意味します。つまり、コミュニティはこれを再実装する代わりに、この基盤の上に構築することができます。
以下に翻訳されたテキストを示します。
このドキュメントは、プロジェクト名の技術仕様を記述しています。
このプロジェクトは、目的を達成するために、チーム名によって実施されます。
主な登場人物は以下の通りです:
- ジョン・スミス (開発者)
- ジェーン・ドウ (プロジェクトマネージャー)
このプロジェクトは、会社名の戦略の一環として実施されます。
詳細については、こちらを参照してください。
連絡先:担当者名 (email@example.com)
- Agashe, J. Han, S. Gan et al. Agent-S: An open agentic framework that uses computers like a human, 2024. arXiv:2410.08164.
- Anthropic. Claude code overview, 2025.
- S. Bai et al. Qwen2.5-VL Technical Report, 2024.
- K. Cheng et al. SeeClick: Harnessing GUI grounding for advanced visual GUI agents, 2024. arXiv:2401.10935.
- L. Feng, Z. Xue, T. Liu, B. An. Group-in-group policy optimization for LLM agent training, 2025. arXiv:2505.10978.
- T. Fu et al. GUI-G2: Gaussian reward modeling for GUI grounding, 2025. arXiv:2507.15846.
- Z. Gu et al. UI-Venus technical report, 2025. arXiv:2508.10833.
- HKUDS. CLI-Anything: Making all software agent-native, 2026.
- W. Hong et al. CogAgent: A visual language model for GUI agents, 2024. arXiv:2312.08914.
- J. Hu et al. Reinforce++: stabilizing critic-free policy optimization, 2025. arXiv:2501.03262.
- Q. Kong et al. MobileWorld: Benchmarking autonomous mobile agents, 2025. arXiv:2512.19432.
- H. Lai et al. AutoWebGLM: A large language model-based web navigating agent, 2024. arXiv:2404.03648.
- H. Lai et al. ComputerRL: Scaling end-to-end online RL for computer use agents, 2025. arXiv:2508.14040.
- K. Li et al. ScreenSpot-Pro: GUI grounding for professional high-resolution computer use, 2025.
- Y. Liu et al. InfiGUI-R1: From reactive actors to deliberative reasoners, 2025. arXiv:2504.14239.
- Z. Lu et al. UI-R1: Enhancing efficient action prediction of GUI agents via RL, 2025. arXiv:2503.21620.
- D. Luo et al. Vimo: Generative visual GUI world model for app agents, 2025. arXiv:2504.13936.
- R. Luo et al. GUI-R1: A generalist R1-style vision-language action model for GUI agents, 2025. arXiv:2504.10458.
- H. Mozannar et al. Magentic-UI, 2025.
- S. Nayak et al. UI-Vision: A desktop-centric GUI benchmark, 2025.
- NousResearch. Hermes-Agent, 2026.
- Y. Qin et al., 2025.
- J. Schulman et al. Proximal policy optimization algorithms, 2017. arXiv:1707.06347.
- B. Seed. Seed1.8 model card: Towards generalized real-world agency, 2026. arXiv:2603.20633.
- Z. Shao et al. DeepSeekMath: Pushing the limits of mathematical reasoning, 2024. arXiv:2402.03300.
- G. Sheng et al. HybridFlow: A flexible and efficient RLHF framework, 2025.
- Y. Shi et al. MobileGUI-RL: Advancing mobile GUI agent through RL in online environment, 2025. arXiv:2507.05720.
- P. Steinberger and OpenClaw Contributors. OpenClaw, 2026.
- F. Tang et al. GUI-G2, 2025a. arXiv:2507.15846.
- F. Tang et al. Think twice, click once, 2025b. arXiv:2503.06470.
- F. Tang et al. A survey on (M)LLM-based GUI agents, 2025c. arXiv:2504.13865.
- V. Team et al. UI-Venus-1.5 technical report, 2026. arXiv:2602.09082.
- H. Wang et al. UI-TARS-2 technical report, 2025. arXiv:2509.02544.
- J. Wang et al. Mobile-Agent-v2, 2024a. arXiv:2406.01014.
- X. Wang et al. MMBench-GUI, 2025.
- Y. Wang et al. OpenClaw-RL, 2026. arXiv:2603.10165.
- J. Wener. OpenCLI, 2026.
- Z. Wu et al. OS-Atlas: A foundation action model for generalist GUI agents, 2024. arXiv:2410.23218.
- H. Xu et al. Mobile-Agent-v3.5, 2026. arXiv:2602.16855.
- Y. Xu et al. Aguvis: Unified pure vision agents for autonomous GUI interaction, 2024. arXiv:2412.04454.
- C. Zhang et al. AppAgent, 2023. arXiv:2312.13771.
- H. Zhou et al. MAI-UI technical report, 2025. arXiv:2512.22047.
- C. Zheng et al. Group sequence policy optimization, 2025. arXiv:2507.18071.
- Y. Zheng et al. Code2World, 2026. arXiv:2602.09856.
- 元のPDFファイルに完全な引用情報が記載されています: arXiv:2604.11784.