ML研究のための自律的な長期エンジニアリングへ
概要
自律型AI研究は急速に進歩していますが、長期間にわたる機械学習の研究開発は依然として困難です。エージェントは、タスクの理解、環境設定、実装、実験、デバッグにおいて、数時間から数日間にわたって一貫した進歩を維持する必要があります。私たちは、単純な原則に基づいたシステムであるAiScientistを紹介します。その原則とは、「優れた長期間のパフォーマンスには、構造化されたオーケストレーションと、持続可能な状態の連続性が不可欠である」ということです。AiScientistは、階層的なオーケストレーションと、権限範囲が設定されたFile-as-Busワークスペースを組み合わせたものです。上位レベルのオーケストレーターは、簡潔な要約とワークスペースマップを通じて、ステージレベルの制御を維持し、特殊なエージェントは、分析、計画、コード、実験データなどの持続可能な成果物に繰り返し再帰的に基づき、主に会話による情報伝達に依存するのではなく、「薄い制御で厚い状態を管理する」ことを実現します。2つの補完的なベンチマークにおいて、AiScientistは、最高の既存のベースラインと比較して、PaperBenchのスコアを平均10.54ポイント向上させ、MLE-Bench Liteでは81.82%のAny Medal%を達成しました。アブレーション研究により、File-as-Busプロトコルがパフォーマンスの重要な要因であることがさらに示されました。このプロトコルを取り除くと、PaperBenchのスコアが6.41ポイント、MLE-Bench Liteのスコアが31.82ポイント低下します。これらの結果は、長期間にわたる機械学習の研究開発は、局所的な推論の問題ではなく、専門的な作業を耐久的なプロジェクトの状態と連携させるシステムの問題であることを示唆しています。
概要:3つのアイデア
Thin Control over Thick State
Orchestratorは、ステージ間の移行においても、わずかながら安定したコンテキストのみを保持します。プロジェクトの重要な状態情報(ペーパー分析、計画、コード、ログ、実験記録など)は、会話の範囲外にある、アクセス権限が設定された共有ワークスペースに保存されます。
File-as-Bus Coordination
エージェントは、チャットではなく、役割に合わせたアーティファクト領域(`paper_analysis/`, `submission/`, 追記専用ログ)を読み書きすることで連携します。 この機能を削除すると、MLE-Bench Lite Any メダルのスコアが 31.82 ポイント低下します。
ベンチマークで裏付け
PaperBenchは、最も優れた既存モデルと比較して、平均で10.54ポイントの改善が見られました。MLE-Bench Liteは、81.82%の「あらゆるメダル」を獲得しました。これらの改善は、Gemini-3-FlashとGLM-5の両方の基盤構造で確認されました。
1. 導入
科学研究の自動化は、人工知能における最も野心的な目標の一つとして浮上しています。特に機械学習(ML)においては、この進歩は、研究の発見を大幅に加速させ、再現性を向上させ、高品質な研究システムへのアクセスを広げる可能性があります。
このより広範な目標の中で、私たちはより実践的な課題に取り組んでいます。機械学習研究のための自律的な長期的なエンジニアリング。エージェントは、機械学習研究システムの構築、実行、そして数時間から数日かけて反復的に改善するという、エンドツーエンドの技術的な作業を自律的に行う必要があります。具体的には、問題は、仕様の不備、システム構築の負担、実験からのフィードバックの遅延と、しばしば誤った情報、そして反復処理を通して状態の一貫性を維持する必要性から生じます。
この課題に対し、私たちはAiScientistというソリューションを提供します。私たちの中心的な設計原則は、長期的なパフォーマンスを、オーケストレーションと状態の連続性の複合的な問題として捉えることです。エージェントは、異なる段階で作業を調整するだけでなく、プロジェクトの状態を十分に忠実に維持し、後続の意思決定がそれを安全に活用できるようにする必要があります。
私たちの貢献
- ここでは、AiScientistをご紹介します。これは、研究仕様の解釈から実行可能なシステムの構築、実験、そして反復的な改善まで、機械学習研究の全プロセスを自動化するシステムです。
- 我々は、階層的なオーケストレーションと、アクセス権限に基づいた共有ワークスペースを組み合わせた、アーティファクト媒介型連携のデザインを提案します。ファイルバスプロトコルを通じて、システムは永続的なアーティファクトによって状態の一貫性を維持し、同時に上位レベルの制御を軽量に保ちます。
- AiScientistをPaperBenchとMLE-Bench Liteで評価し、強力なベースラインと比較して大幅な改善が見られ、長期的な機械学習研究におけるエンジニアリング、特に持続可能な状態の連続性の重要性に関する実証的な洞察が得られました。
2. タスクの定式化
我々は、PaperBenchを通じて、長期的な機械学習研究エンジニアリングタスクを定義します。与えられた研究論文P、GPUアクセス可能なシンプルなDocker環境E、および時間予算Tに対し、エージェントは、論文のターゲットメトリクスを再現する実行可能な成果物を生成する必要があります。
このことが難しい理由となる4つの課題:
研究仕様は、通常、完全な設計図というよりも不完全なものです。重要な実装に関する詳細は、しばしば暗黙のものであり、セクションのあちこちに散らばっていたり、完全に省略されていたりするため、エージェントは限られた情報からそれらを推測する必要があります。
成功は、アルゴリズムの実装だけでなく、広範な準備作業にかかっています。具体的には、環境の構築、許可されたソースからデータセットとモデルの取得、そしてこれらのリソースを動作可能なシステムに統合することが必要です。
実験が実施されて初めて、意味のある証拠が得られます。矛盾は、解釈、実装、データ処理、またはインフラストラクチャに起因する可能性があります。したがって、エージェントは、遅延し、しばしば誤った情報を含む信号に基づいて推論する必要があります。
各ラウンドでは、コード、設定ファイル、ログ、結果、および診断データが生成され、これらの情報は、その後の判断を下す際に正しく解釈され、活用されなければなりません。進捗は、イテレーション(反復)を通じて一貫性を維持することにかかっています。
3. AiScientist: アーティファクトを活用した研究ラボ
AiScientistは、長期的な機械学習研究エンジニアリングにおけるシンプルなシステム観に基づいて構築されています。優れたパフォーマンスは、作業を適切な段階に分解することだけでなく、プロジェクトの状態を十分に忠実に維持することで実現されます。これにより、後続の決定が安全にそれに基づいて行えるようになります。Tier-0のオーケストレーターは、簡潔な概要とワークスペースマップを通じて、ステージレベルの制御を維持し、Tier-1の専門家と、オプションのTier-2のサブエージェントは、共有され、アクセス権が設定されたワークスペース上で動作します。
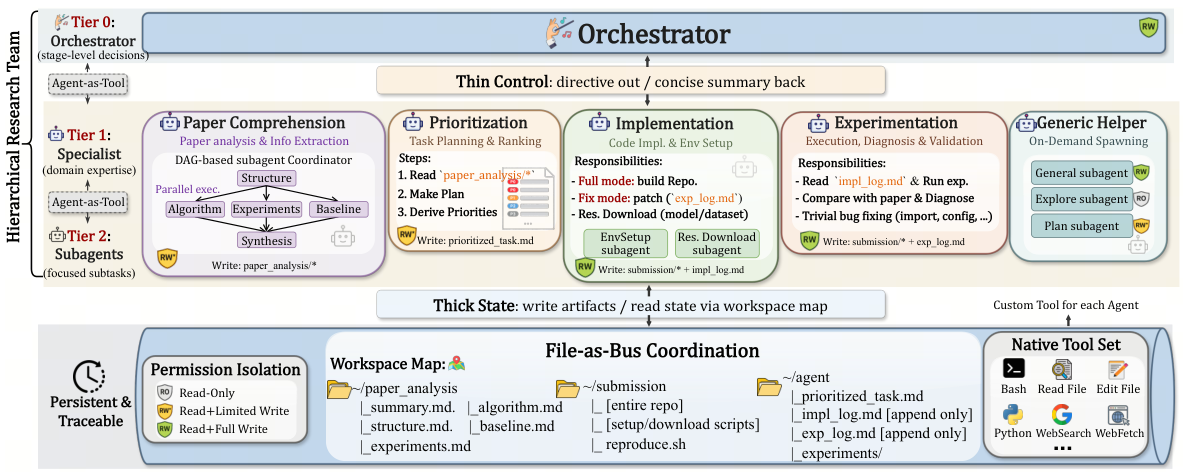
3.1. Thin Control over Thick State
AiScientistの中核となるシステム原則は、制御は最小限に、状態は最大限にです。ここで、thinとは、ルーチンな制御判断を行うために必要な、小さく安定したコンテキストを指し、thickとは、反復処理を通じて一貫性を保つ必要のある、はるかに大きな外部化されたプロジェクトの状態を指します。
ステップtにおける作業領域をW_tと表記します。軽量な作業領域マップm_tは、主要な成果物領域とその役割をテキスト形式で索引としたものです。
定式化
作業領域マップ:これは、アーティファクト領域のテキストによる索引であり、作業領域へのナビゲーションインターフェースです。情報が失われたり、置き換えられたりするものではありません。
$$m_t = \mathcal{M}(W_t)\tag{1}$$
オーケストレーターのアクション選択:上位レベルのコントローラーは、ステージレベルのコンテキストとワークスペースマップを使用して、次のアクションを選択します。必要に応じて、ワークスペースをオンデマンドで検査することも可能です。
$$a_t = \mathcal{T}_0(c_t, m_t, G; W_t),\ a_t \in \mathcal{T}_0 \cup \mathcal{A}_1 \tag{2}$$
専門家による呼び出し: 専門家は独自のローカルループを実行し、簡潔な概要とワークスペースの更新情報のみを返します。
$$(s_t, \Delta W_t) = \tau_j(d_t, m_t; W_t),\quad c_{t+1} = c_t \oplus s_t,\quad W_{t+1} = U(W_t, \Delta W_t) \tag{3}$$
数式に数学的な知識がなくても
式(1)~(3)は、見慣れない記号で難しそうに見えますが、それぞれが非常に具体的な、日常的な操作を表しています。
- (1)
m = M(W): プロジェクトフォルダ全体に対して、自動的に目次を生成します。目次は短く、フォルダは巨大です。 - (2) オーケストレーターがアクションを選択: 上司は目次と短い状況報告を確認し、"シェルコマンドを実行"するか、"ペーパー・コンプレヘンションの専門家を呼び出す"かを判断します。長々とチャット履歴を確認する必要はありません。
- (3) 専門家が対応: 専門家は内部処理を行い、ファイルを作成または編集し、2行の要約と変更されたファイルのリストを返します。上司は要約のみを確認します。
この表記では隠されていますが、重要な点は以下の通りです。
この設計は、制御と引き継ぎのレベルにおいて、段階的な情報開示を実現しています。Orchestratorは、ステージ間の移行に関わらず、わずかながら安定した制御インターフェースを提供し、蓄積されたチャット履歴ではなく、概要や地図に基づいて判断を行います。
3.2. ファイルをバスとして連携させる方法
AiScientistは、File-as-Busプロトコルによるアーティファクトを介した連携を実現します。長期間にわたる機械学習研究開発において、重要な中間状態は、すでにファイルとして扱われるものが多く存在します。具体的には、論文の分析、環境構築スクリプト、リソースダウンロードのマニフェスト、トレーニングコード、チェックポイント、評価指標、および追記専用の実行ログなどです。ワークスペースは、単なる保存場所ではなく、システム・オブ・レコードとして扱われます。
3 つの役割別アーティファクト領域
paper_analysis/
submission/
reproduce.sh` という実行ファイルが含まれており、これは Implementation and Experimentation の専門家によって作成されました。impl_log.md · exp_log.md
状態が共有チャットではなく、永続的な成果物に記録されているため、エージェントは現在のワークスペースの状態からプロジェクトを再開し、タスクに関連する領域を読み取り、完全な過去のやり取りを必要とせずに操作することができます。
アナロジー:SlackとGit
多くのマルチエージェントシステムは、Slackのスレッドのようなものを使って連携しています。メッセージと返信が積み重なり、誰もが何もを見つけられなくなります。File-as-Busは、Git + 共有リポジトリのように連携します。各エージェントは現在のファイルを読み込み、変更を行い、それを書き戻し、次のエージェントはそのファイルから処理を開始します。チャット履歴の400ものメッセージから始めるわけではありません。そのため、File-as-Busは、以前のエージェントでは対応できなかった、24時間連続の自律的な実行にも対応できます。
3.3. Agent-as-Tool による階層オーケストレーション
File-as-Bus連携が状態の基盤を提供するのに対し、階層的なオーケストレーションが制御メカニズムを提供します。 Orchestratorは、理解から計画、実行、実験、デバッグに至るまで、適切な専門知識を適切な段階に振り分けます。一方、専門家はそれぞれのローカルなサイクルを実行し、Tier-2のサブエージェントが、特定の、より細かなタスクを担当します。
主要な設計思想はAgent-as-Toolです。各スペシャリストは、シェル実行、ファイル検査、ウェブ検索といった通常のツールと同様の呼び出し可能インターフェースを通じて、Orchestratorに接続します。委任は、Orchestratorの通常のツール利用フロー内のアクションであり、各スペシャリストのプライベートなコンテキストは、各呼び出しごとに再初期化されるため、詳細な推論が上位レベルに累積されることはありません。
Tier-1 Specialists
この論文の内容を、実装の詳細、目標とする指標、および不確実性に関する記述に変換します。複数のサブエージェントを連携させ、独立した分析軸を並行して処理し、その後で統合することができます。
論文の内容を理解し、それに基づいて実行可能な契約を策定します。具体的には、依存関係を特定し、マイルストーンを重要度と実現可能性に基づいてランク付けし、その計画を`prioritized_tasks.md`というファイルに記述します。
計画や問題報告をコードに変換します。フルモードでは、分析データと優先順位付けされた計画に基づいて、再現可能なリポジトリを構築します。修正モードでは、指示に基づいて既存のコードベースを修正します。
エンドツーエンドのパイプラインを実行し、生成されたメトリクスを論文の目標値と比較し、結果と未解決の問題を`exp_log.md`に記録します。
補助的なタスク、例えば探索、計画、または特定の状況下での一時的な作業などを行うための、軽量なヘルパー機能を生成します。これらのタスクは、専門家による専用のワークフローを必要としない場合に役立ちます。
Tier-2 サブエージェントは、専門家のローカルな範囲内で作成される、特定の機能に特化した基盤となるワーカーです。これには、構造抽出、アルゴリズムとベースラインの分析、環境構築、リソースのダウンロード、および予備調査が含まれます。
3.4. データに基づいた研究・開発サイクル
AiScientistは、固定された一方向のパイプラインではなく、進化し続ける作業領域全体にわたる、エビデンスに基づいた研究・エンジニアリングのサイクルを運用します。 プロジェクトの初期段階では、Orchestratorは論文の理解と優先順位付けを重視し、明確でランク付けされた計画に基づいて実装を進めます。 一度、基本的なフレームワークが構築されると、主要なパターンは実装と実験の反復的な交互になります。
このループは、実行可能な証拠によって駆動されます。実験的な実行では、失敗トレース、部分的な成功、メトリックの欠落、およびリソースのボトルネックが発生し、次に何を構築、修正、またはテストすべきかを決定します。これらの出力は、永続的な成果物として記録され、将来の反復処理でそれらを正確に分析できるようにします。
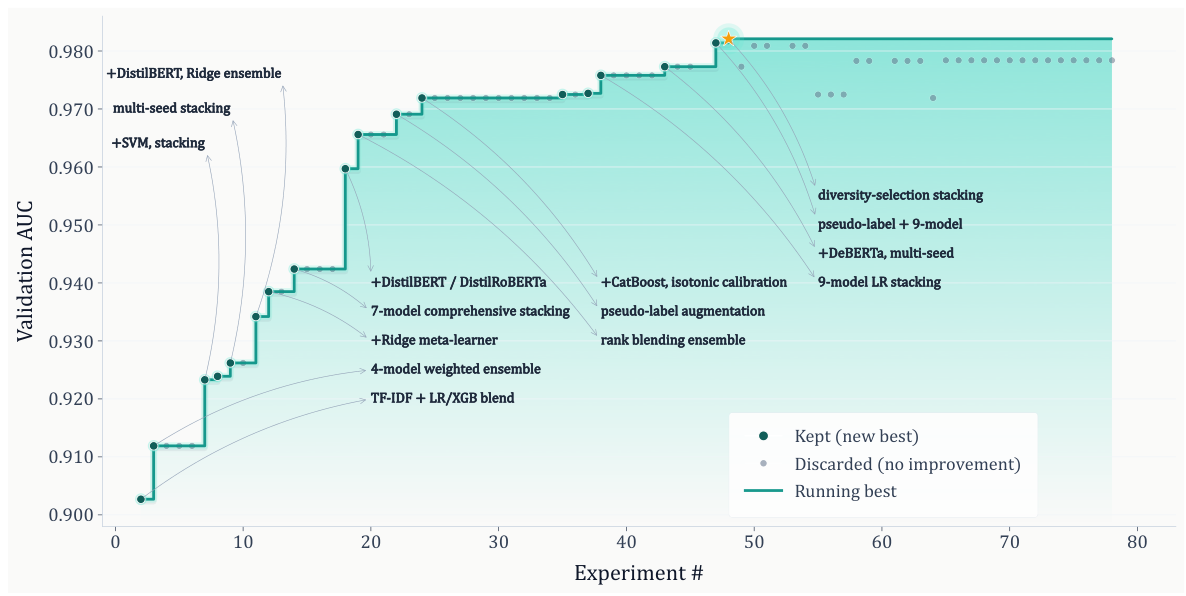
4.1. 実験装置
ベンチマーク
最先端の学会論文を、完全にゼロから再現します。エージェントが、未知の論文から、シンプルなDocker環境内で動作する再現結果を得られるかどうかを評価します。
Kaggleのような機械学習コンペティションは、継続的な実験による改善を重視します。成功には、単一の提出物だけでなく、多くの反復的な改善のプロセスが必要です。
ベースライン
PaperBenchでは、同じ評価プロトコルに基づいて、BasicAgent および IterativeAgent との比較を行っています。MLE-Bench Liteでは、高度な自律型機械学習エンジニアリングシステム(AIDE, LoongNow, ML-Master)との制御された比較結果を報告し、さらに、公式のランキング結果を参考情報として追加しています。
実装詳細
`AiScientist` は、2つのバックボーン LLM である `Gemini-3-Flash` と `GLM-5` を使用してインスタンス化されます。両方のベンチマークにおいて、各実行には 1 つの H20 GPU と、タスクごとに 24 時間の予算が割り当てられます。
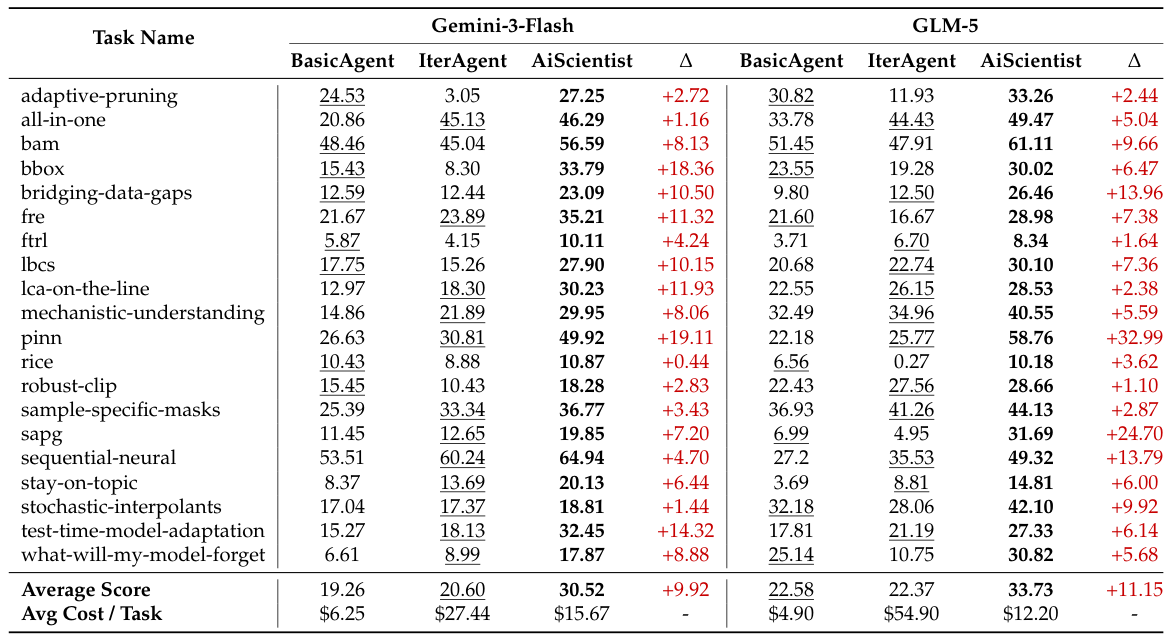
4.2. PaperBenchに関する主な結果
両方のバックボーンにおいて、AiScientistは、最も優れたベースラインと比較して、それぞれ9.92ポイントと11.15ポイントの改善が見られました。また、48時間の努力の後、報告されている人間のベースラインである41%との差を縮めることができました。
IterativeAgentと比較して、AiScientistは、はるかに低いコストでタスクあたり、大幅に高い平均スコアを達成します。Gemini-3-Flash環境下では、$15.67 vs $27.44、GLM-5環境下では、$12.20 vs $54.90です。この改善は、単にインタラクション時間を増やすことによって得られたものではありません。
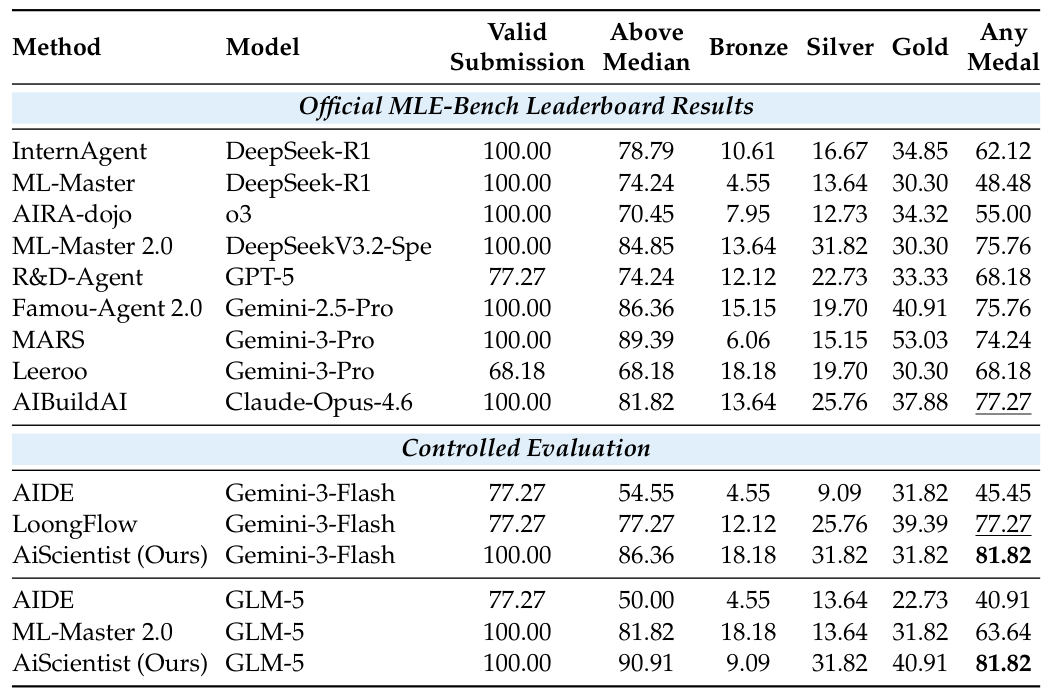
4.3. MLE-Bench Lite に関する主要な結果
MLE-Bench Liteは、PaperBenchを補完するものであり、競争形式の機械学習タスクにおける継続的な実験改善に焦点を当てています。この種のタスクでは、成功は単一回の再現性だけでなく、エージェントがパイプラインを反復的に改善できるかどうかに大きく依存します。
制御された評価において、AiScientistは、どちらの基盤モデルにおいても最も優れた総合パフォーマンスを発揮しました。Gemini-3-FlashとGLM-5の両方で、同じ81.82のAny Medal%を達成し、最も優れた対照モデルと比較して、それぞれ4.55ポイントと18.18ポイントの改善が見られました。これは、表2に記載されているすべてのレポートされたリーダーボードのAny Medalの値よりも高い数値です。
4.4. 動作原理の分析
私たちは、AiScientistがもたらす成果を説明するメカニズムを分析します。主に2つの問いに焦点を当てます。それは、持続可能な成果に基づく継続性が主要な要因であるかどうか、そして、より単純で階層構造を持たない組織構造で十分であるかどうか、ということです。
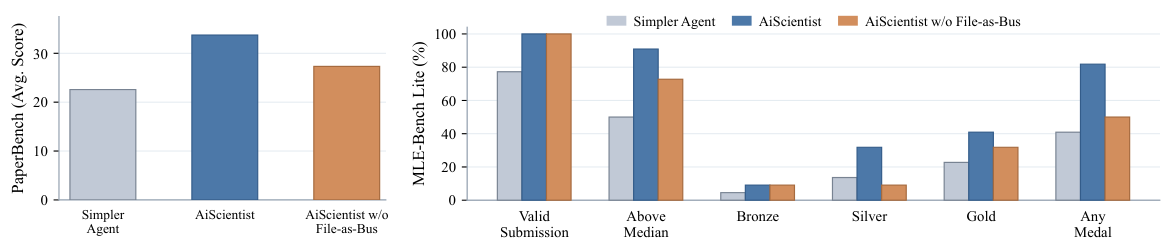
File-as-Bus アブレーション
`File-as-Bus`の機能を削除すると、`PaperBench`のスコアが6.41ポイント低下し、`MLE-Bench Lite Any Medal`のスコアが31.82ポイント低下します。`Valid Submission`と`Bronze`のスコアはほぼ変化しませんが、スコアの低下は主に、中央値より高い、`Silver`、`Gold`といった、より高いパフォーマンスを示す指標に集中しています。耐久性のある成果物は、最初の提出物よりも、後続のラウンドでの改善において重要です。
より単純な Agent 構成との比較
この効果は、単にインタラクションの量を増やすだけのものではありません。`IterativeAgent` はすでに `BasicAgent` よりも多くのインタラクションを提供していますが、それでも `AiScientist`(`File-as-Bus` を使用しない場合)に劣っています。これは、階層的なオーケストレーションが、単に会話の時間を長くすること以上の価値をもたらすことを示しています。
なぜ「Valid Submission」は生き残るが、「Gold」はFile-as-Busなしでは崩壊するのか
この非対称性は、アブレーション実験で最も興味深い結果の一つです。 動作可能な最初の試作品では、エージェントが任意の実行可能なパイプラインを生成するだけで済みます。 良好な実装の1回で十分な場合が多く、永続的な状態を失っても大きな影響はありません。 一方、金メダルを獲得するには、数十回の反復的な改善が必要であり、各ラウンドでは、以前のラウンドのすべての調整、実験の失敗、およびメトリック履歴に基づいて正しく構築する必要があります。 信頼性の高いアーティファクト記録は、まさにこの点で重要な役割を果たします。 それがないと、エージェントはすでに決定したことを何度も再計算し、何が試され、何が試されなかったかという情報が失われます。
製品に関する考察: 長期間動作するAIエージェントを構築していて、「最初に動作するバージョン」以降に性能が頭打ちになる場合は、まずLLMの問題ではなく、状態の一貫性に関する問題を疑うべきです。
6. 結論
自律的な長期的な機械学習研究エンジニアリングは困難です。なぜなら、失敗が後になって顕在化し、その原因が解釈、実装、およびインフラストラクチャにわたって複雑に絡み合っている場合があり、また、進捗が繰り返される実装・実験サイクルを通じて一貫性を保つ必要があるからです。AiScientistは、これをシステムの問題として捉え直しました。これは、持続可能なプロジェクトの状態において、専門的な作業を調整することを意味します。そして、階層的なオーケストレーションとFile-as-Busによる連携を組み合わせることで、PaperBenchとMLE-Bench Liteの両方で大幅な改善が得られることを示しました。我々は、この「薄い制御による厚い状態の管理」という原則が、将来の長期的な自律的な研究システムにとって有用な視点を提供すると期待しています。